







什么是RAG
RAG,全称Retrieval-Augmented Generation,即检索增强生成。它如同为大模型配备了一把通往浩瀚知识宝库的钥匙,让AI能够更精准、更贴合你的需求。
- 检索 (Retrieval): 好比在图书馆查找资料。当用户提出问题时,RAG 会根据问题的关键词、语义等信息,在外部知识库中进行检索,找到与问题相关的文档或片段。这个阶段的关键在于高效的检索算法,例如基于关键词的倒排索引、基于语义向量的相似度搜索等。更高级的检索技术还会考虑文档的质量、权威性等因素。
- 增强 (Augmentation): 将检索到的相关文档或片段,作为上下文信息添加到用户的提问中。这就像在阅读资料的基础上,带着更明确的问题去请教专家。增强阶段的关键在于如何有效地整合检索到的信息,避免信息过载或引入噪声,例如选择最重要的片段、对片段进行排序、或者将多个片段进行融合等。
- 生成 (Generation): 大模型基于增强后的输入信息生成最终的答案。此时,大模型不仅拥有预训练的通用知识,还获得了与问题相关的特定领域知识,从而能够生成更准确、更专业的答案。
我的老师曾经打过一个比喻,我觉得非常贴切,“RAG就是开卷考试”,这个比喻真的是非常的贴切,完美的说明了RAG的逻辑,用现在流行的话说,听君一席话,茅塞顿开。确实,RAG其实就是给你很多书,然后问你问题,问题就在书里,你可以去里面找,然后回答。这时候,RAG的原理很清晰了,但问题也很清晰了,怎么才能快速的找到问题对应的答案?没错,这其实就是RAG技术的核心问题。
我们会基于大模型分发助手平台,看下RAG的实际流程。
从封闭走向开放:RAG 为何如此重要?
传统的大模型,例如GPT系列,依赖于预训练阶段学习到的知识。这就像一个博览群书的学者,拥有丰富的知识储备。然而,这些知识是“固化”的,无法根据用户的特定需求进行更新或调整。这就导致了大模型在处理特定领域问题、或者需要结合用户私人信息时,显得力不从心。
RAG 的出现打破了这一局限。它不再仅仅依赖于预训练的知识,而是将目光投向了广阔的外部世界——你的私人文档、专业数据库、特定领域的知识图谱等等。通过检索这些外部信息,RAG 为大模型注入了源源不断的“新鲜血液”,让它能够根据用户的需求,动态地获取知识,从而生成更精准、更个性化的答案。
向量数据库
在 RAG 出现之前,知识检索主要依赖于关键词匹配。这种方式简单直接,但存在明显的局限性:
- 无法捕捉语义相似性: 即使两个文档表达的意思相同,如果使用的关键词不同,也可能无法被检索到。
- 容易受到噪声干扰: 无关的关键词可能会干扰检索结果,导致检索精度下降。
RAG 的出现,对知识检索提出了更高的要求。RAG 需要的是能够理解语义、关联上下文、并进行推理的知识检索方式。传统的关键词搜索显然无法满足这些需求。
为了解决这个问题,人们开始将目光转向向量搜索。通过将文本转换成向量表示,可以在向量空间中进行相似性搜索,从而更有效地捕捉文本之间的语义关系,即使文档中没有出现与问题完全相同的关键词,也能找到相关的文档。
比较流行的开源向量数据库
- Faiss (Facebook AI Similarity Search): 由 Facebook AI Research 开发,专注于高效的相似性搜索和聚类。它支持多种索引算法,并针对 GPU 进行了优化,具有非常高的性能。适合大规模数据集和高性能要求的场景。
- Annoy (Spotify Approximate Nearest Neighbors Oh Yeah): 由 Spotify 开发,专注于近似最近邻搜索。它使用树形结构进行索引,具有较低的内存占用和较快的查询速度。适合对精度要求不高,但对速度和内存占用敏感的场景。
- ScaNN (Scalable Nearest Neighbors): 由 Google Research 开发,专注于可扩展的近似最近邻搜索。它采用了一种新的量化方法,可以在保持高精度的前提下,显著降低内存占用和查询延迟。适合处理超大规模数据集的场景。
- Milvus: 一款开源的云原生向量数据库,支持多种索引类型和相似性度量方法。它具有良好的可扩展性和易用性,并提供丰富的 API 和工具。适合构建企业级向量搜索应用。
- Qdrant: 一款开源的向量相似性搜索引擎,专注于过滤和全文搜索功能。它支持多种数据类型,并提供丰富的 API 和 SDK。适合需要复杂过滤条件的场景。
- Vespa: 由雅虎开发的开源搜索引擎,支持向量搜索和全文搜索。它具有高性能、高可用性和可扩展性,并提供丰富的功能,例如地理空间搜索、实时索引等。适合构建复杂的搜索应用。
- Chroma: 一个开源的嵌入数据库,专为 LLM 应用设计。它专注于易用性和快速原型设计,并与 Python 生态系统紧密集成。它提供了一个简单的 API 用于存储、检索和管理嵌入,并支持本地部署和云部署。
传统的数据库主要处理结构化数据,而 RAG 需要处理的是大量的非结构化数据,例如文本、图像、音频等。如何高效地从这些海量数据中检索到与用户提问相关的知识,是一个巨大的挑战。向量数据库的出现,为解决这个问题提供了新的思路。
向量数据库将非结构化数据转换成向量表示,并存储在高维向量空间中。当用户提出问题时,RAG 系统首先将问题转换成向量,然后在向量空间中搜索与问题向量最相似的文档向量。这种基于向量的检索方式,能够高效地捕捉文本之间的语义相似性,即使文档中没有出现与问题完全相同的关键词,也能够找到相关的文档。
向量数据库如何赋能 RAG:
- 高效的相似性搜索: 向量数据库针对高维向量搜索进行了优化,能够快速地从海量数据中找到与问题最相似的文档。
- 灵活的知识表示: 向量可以表示各种类型的非结构化数据,使得 RAG 系统能够处理更丰富的知识类型。
- 动态的知识更新: 向量数据库可以方便地添加、删除和更新文档,使得 RAG 系统能够快速适应新的知识。
RAG 与向量数据库的未来发展趋势:
- 更丰富的向量表示: 未来的向量数据库将支持更丰富的向量表示方法,例如结合知识图谱、深度学习模型等,提高向量表示的准确性和表达能力。
- 更智能的检索算法: 研究更先进的向量检索算法,例如基于图神经网络的检索、基于深度学习的语义检索等,进一步提高检索的效率和精度。
- 更紧密的软硬件结合: 开发专门针对向量数据库的硬件加速器,例如 GPU、FPGA 等,进一步提升向量数据库的性能。
- 更广泛的应用场景: 随着 RAG 和向量数据库技术的不断成熟,它们将在更多领域得到应用,例如智能搜索、个性化推荐、知识图谱构建等。
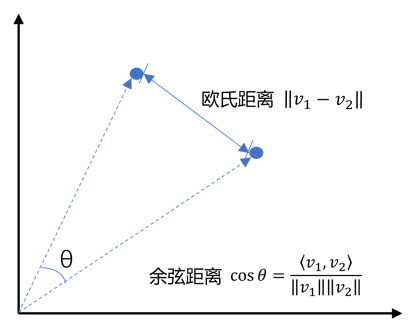
欧氏距离与余弦距离
在检索阶段,如何判断用户提问与知识库中文档的相似度至关重要。这里,我们介绍两种常用的相似度计算方法:欧氏距离和余弦距离。
- 欧氏距离: 想象一下二维平面上的两个点,欧氏距离就是连接这两个点的直线距离。在高维空间中,欧氏距离计算的是两个向量之间的直线距离。距离越小,相似度越高。但在文本检索中,欧氏距离容易受到向量长度的影响。例如,一篇长文章和一篇短文章即使主题相同,它们的向量长度也可能相差很大,导致欧氏距离较大,从而被误判为不相似。
- 余弦距离: 更关注两个向量之间的夹角。夹角越小,余弦值越接近1,相似度越高。余弦距离不受向量长度的影响,更适合用于文本检索,因为它更关注文本的语义相似性,而不是文本的长度。
关于这两个距离,我们看下图示会比较清楚
这两个距离的计算,可以认为是RAG-向量数据库的核心了,我们在大模型分发助手看下过程。
RAG的过程
知识
所谓“知识”,就是给大模型的那本书,这里我们只说原理,只导入样例。
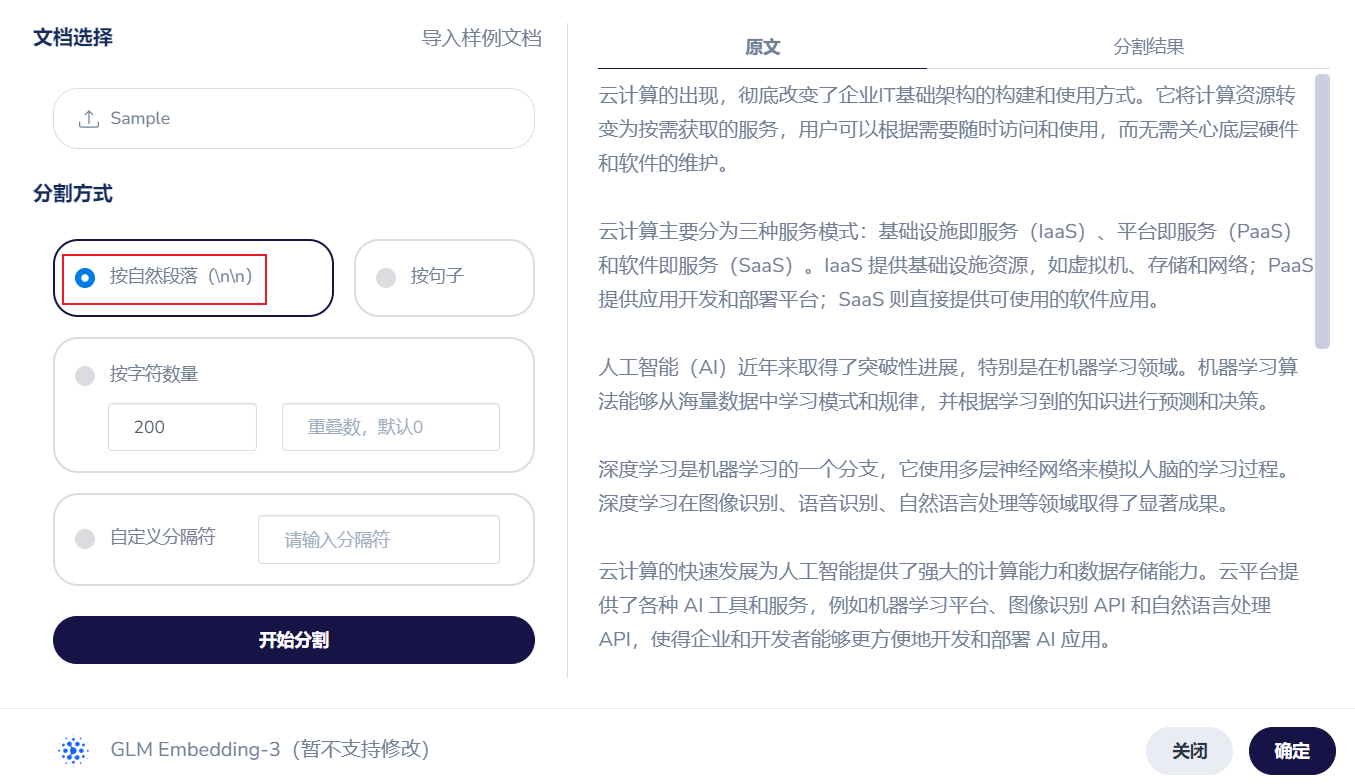
知识切割
知识切割,就是将知识,按照一定的规则,切割成一块一块(Chunk),以每个块为单元,进行向量化比对,针对每个块,计算出他们的向量数据。很明显,块的分割好快,直接决定了回答的效果,所以分割这个事情本身,是个非常讲究的事情。这是个单独的话题,我们不做展开,只使用最基本的一种分割方式“段落分割”来说明RAG的过程。

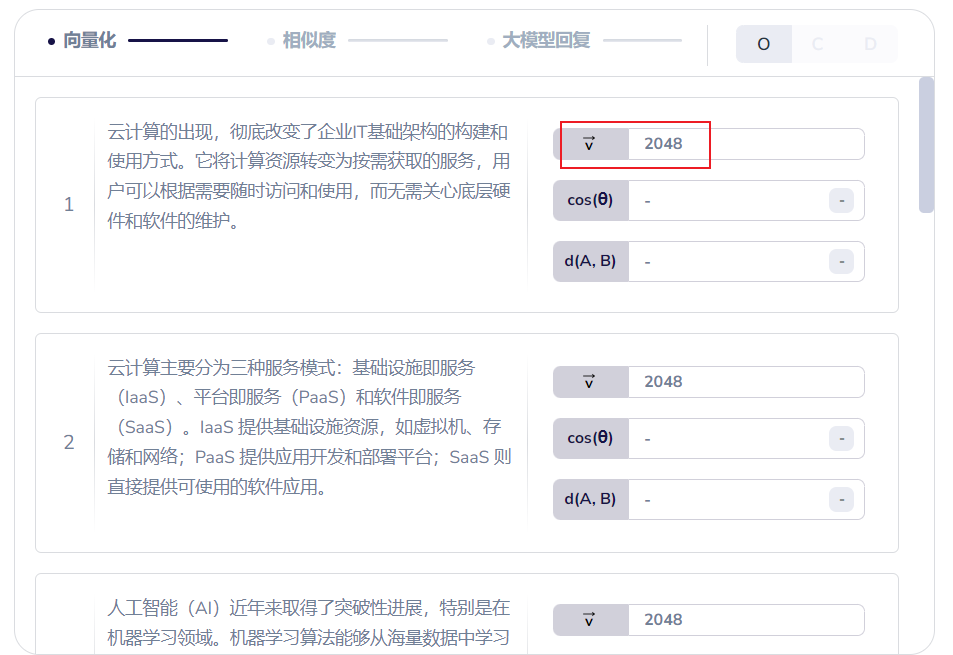
按照前面说的,分割之后,要针对没个块,做向量计算,得到向量数据,这里,我们借助GLM Embedding-3来计算,每个块,得到2048维的向量数组。
提问 & 计算距离
我们的提问内容:谈谈云计算如何促进人工智能的发展?
点击提问,平台会自动计算各个块的欧氏距离和余弦距离,以及他们的距离排名。
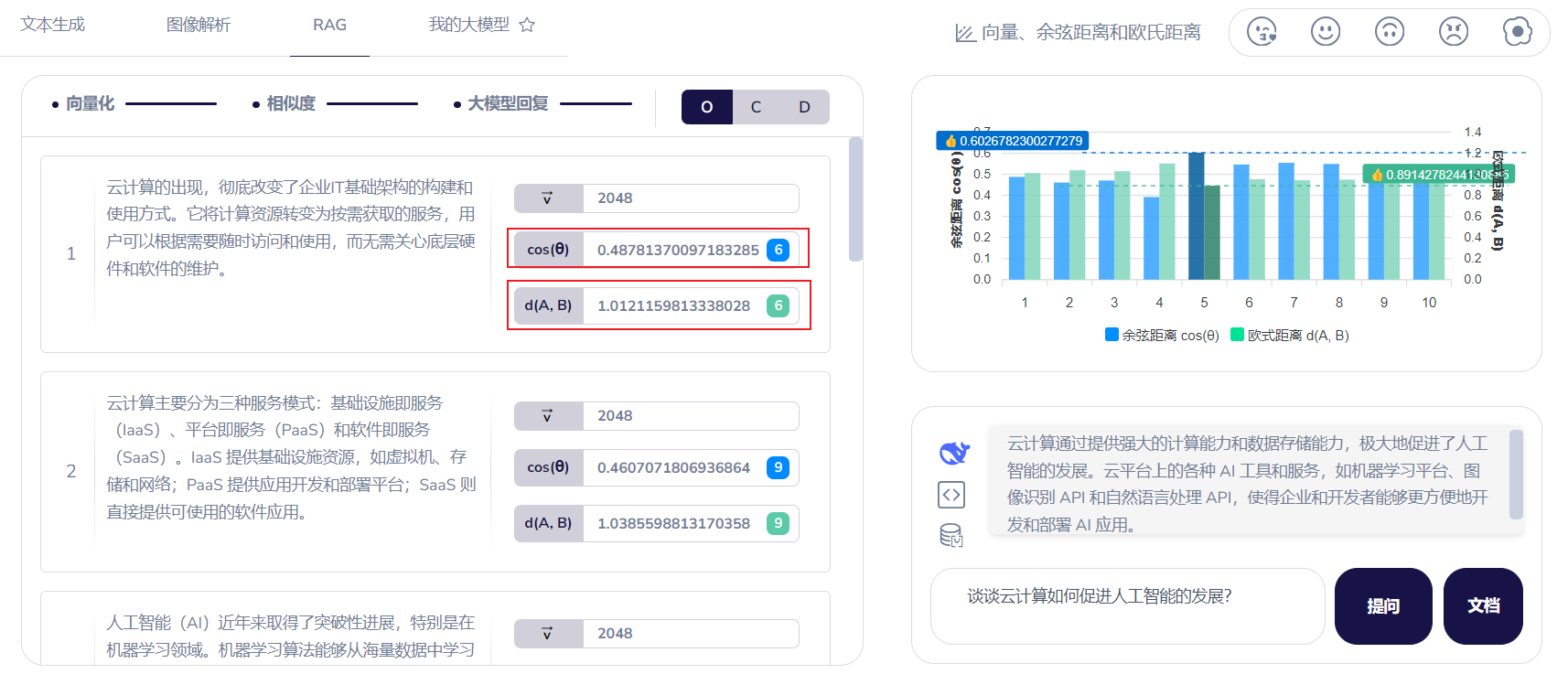

到这里,根据余弦距离和欧式距离,都表明段落5是最匹配的那个块。
提示词
我们需要准备一个提示词,将从匹配到的块的内容,和实际的提问,一并发给大模型,让大模型进行回答,一个简易的提示词模板:
你是一个问答机器人。 你的任务是根据下述给定的知识信息回答用户问题。 知识信息: {context} 用户问: {query} 如果知识信息不包含用户问题的答案,或者知识信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。 请不要输出知识信息中不包含的信息或答案。
{context}:知识变量,相似度对比中,取出余弦距离和欧氏距离最好的Chunk
{query}:查询变量,输入的问题
该提示词,已经内置到了大模型分发助手中,会自动填充context和query。
得到答案
根据模板组装好的最终提示词,发送给大模型,大模型会基于这个匹配到的内容进行回答,并给出最终的结果。
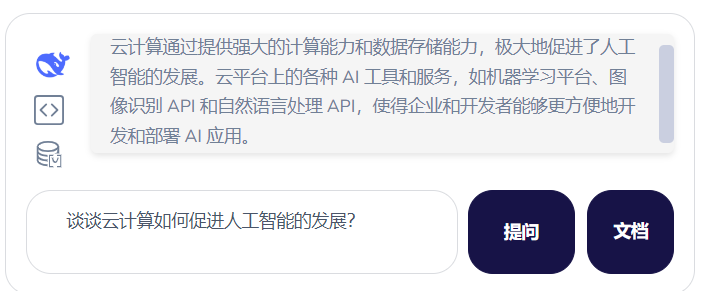
到这里,RAG的过程就算结束了,大家可以去大模型分发助手中感受这个过程,这里只是说明了这几个关键过程,实际生产要复杂的多。
RAG的未来
AG 的优势不仅仅体现在几个简单的关键词上,它代表着一种全新的 AI 范式,为我们带来了更强大、更灵活、更可靠的 AI 应用。
1. 精准性与个性化:摆脱通用知识的束缚
传统的预训练大模型虽然知识储备丰富,但在面对特定领域问题或用户个性化需求时,往往显得力不从心。RAG 通过引入外部知识库,打破了通用知识的束缚,能够根据用户的特定需求和知识库,提供更精准、更个性化的答案。例如,一个医生可以使用基于医疗知识库的 RAG 系统,快速查询疾病信息、诊断病例;一个律师可以使用基于法律知识库的 RAG 系统,查找相关案例、撰写法律文书。
2. 可扩展性与可更新性:持续学习,永不过时
知识是不断更新和发展的,一个静态的知识库很快就会过时。RAG 的优势在于其强大的可扩展性和可更新性。通过连接不同的外部知识库,RAG 可以不断扩展自身的知识范围,并保持知识的更新。例如,可以定期将最新的研究成果、行业动态添加到知识库中,让 RAG 系统始终保持在知识的前沿。
3. 可解释性与可信任性:知其然,更知其所以然
AI 的可解释性一直是一个重要的研究方向。用户不仅想知道答案是什么,更想知道答案是如何得出的。RAG 的答案基于检索到的文档,用户可以清楚地看到答案的来源和依据,从而提高对答案的信任度。这对于一些对可靠性要求较高的领域,例如医疗、金融等,尤为重要。
4. 成本效益与效率提升:更少的训练,更多的产出
相比于重新训练一个大型语言模型以涵盖特定领域知识,使用 RAG 构建一个基于现有大模型和特定领域知识库的系统,成本更低,效率更高。这使得企业和个人能够以更低的成本获得更专业的 AI 能力。
未来展望:迈向认知智能的新时代
RAG 不仅仅是一项技术,更是一种连接大模型与现实世界知识的桥梁。它的出现,为我们描绘了未来 AI 发展的新方向:
- 更深入的知识理解与推理: RAG 将推动大模型从简单的文本生成走向更深入的知识理解和推理,例如理解复杂的因果关系、进行逻辑推理等。
- 更自然的人机交互: RAG 将使人机交互更加自然流畅,例如可以进行更复杂的对话、理解用户的意图、提供更个性化的服务。
- 更广泛的领域应用: RAG 将在更多领域发挥重要作用,例如科学研究、医疗诊断、金融分析、智能制造等,推动各行各业的智能化转型。
总而言之,RAG 代表着 AI 技术发展的一个重要里程碑,它将引领我们迈向一个更加智能、更加便捷、更加美好的未来。
