







大家好,我是不温卜火,是一名计算机学院大数据专业大三的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只在csdn这一个平台进行更新,博客主页:https://buwenbuhuo.blog.csdn.net/。

PS:由于现在越来越多的人未经本人同意直接爬取博主本人文章,博主在此特别声明:未经本人允许,禁止转载!!!
目录

推荐

♥各位如果想要交流的话,可以加下QQ交流群:974178910,里面有各种你想要的学习资料。♥
♥欢迎大家关注公众号【不温卜火】,关注公众号即可以提前阅读又可以获取各种干货哦,同时公众号每满1024及1024倍数则会抽奖赠送机械键盘一份+IT书籍1份哟~♥
一、前言

此篇文章不出意外应该是此系列的最终篇。之所以写这篇博文是因为想到光让学弟学妹们了解数据采集(爬虫)是不行的,数据采集其实只是数据分析的第一步。下面还需要数据清洗以及数据可视化。因此,学长感觉让你们能够多了解一些数据清洗的相关内容是很有必要的。下图即为我们平常所看到的可视化UI界面的整体分析过程。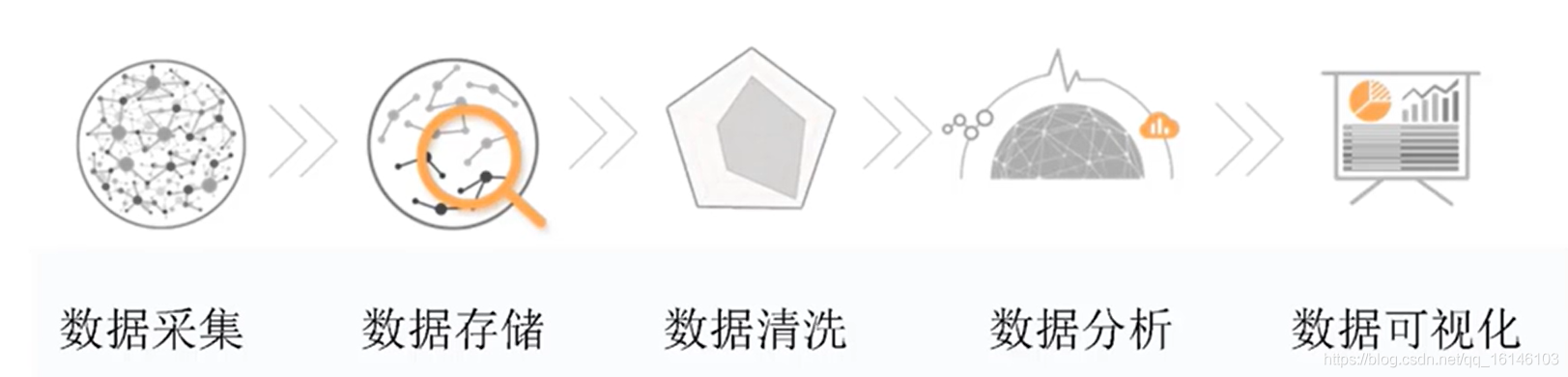
我们知道网络爬虫是一种从互联网上进行开放数据采集的重要手段。但是咱们所收集的数据并不全都是直接能够使用的。它们由于各种原因,原始数据往往会存在许多问题,例如数据格式不正确,数据存在冗余等等。这些我们暂时可以理解为脏数据。
那么直接使用我们获取到的第一手原始数据呢?这个时候我们就需要进行数据清洗。
考虑到学弟学妹们基础较为薄弱,因此学长在此选择一个较为简单的爬虫demo。方便学弟学妹们进行理解。此demo的数据采集部分实现从某图书网站自动下载感兴趣的图书信息的功能。主要实现的功能包括单页面图书信息下载,图书信息抽取,多页面图书信息下载等。本demo学长认为挺适合大数据初学者了解数据采集以及数据清洗的哈哈。
下面这一点是学长个人建议哈~ 学长认为如果进行数据清洗的话,使用Anaconda集成的Jupyter进行操作是很🙆的。
所以此篇文章学长使用的操作环境为:Win10+Anaconda+python3.7
在进行演示之前我们需要知道什么是数据清洗!
数据清洗:为了便于后续的处理和分析,对数据进行的质量诊断、数据整合、数据转换、缺失值处理和异常值处理等操作。
1、数据清洗的方法
1、缺失值处理:对存在缺失的数据进行插补
2、异常值处理:对数据集中存在的不合理值进行处理
3、数据转换:将数据从一种表现形式转换成另一种表现形式
2、数据清洗的工具
1、Mapreduce(Hadoop):基于集群的高性能并行计算框架;并行计算与运行软件框架;并行程序设计模型与方法。
2、Pandas(Python):解决数据分析任务的Python库,提供了诸多数据清洗的函数和方法。
3、OpenRefine:数据清洗工具,能够对数据进行可视化操作,类似Excel,但其工作方式更像数据库。
本demo学长使用Pandas进行数据清洗。
二、准备工作

2.1 官网安装Anaconda(推荐)
安装Anaconda的话,学长建议去官网进行下载安装。
官网链接:https://www.anaconda.com/
点击之后选择自己的操作系统以及版本对应的下载链接
点击后即可自动下载。下载完成后即可安装。
2.2 Anaconda历史版本合集(学长自己的下载方式)
在此,博主推荐两个下载网址:
官网给出的anaconda所有版本链接:https://repo.continuum.io/archive/
清华大学开源软件镜像站:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
2.3 下载建议
两个镜像源地址都可以进行下载,不过第一个为官网版本更新比较完整。学长建议各位下载可以选择官网版本,并且如果下载没必要直接下载最新版本。当然了至于怎样下载主要还是看个人。
2.4 如何在Jupyter Notebook新建文件
我们打开Anaconda之后的界面如下:
那么如何使用Jupyter Notebook呢?下面看我操作:
🆗到这里我们就知道如何新建文件了。下面就开始进入正题了!
三、数据采集

3.1 爬取内容描述和数据来源
爬取内容描述:从当当网搜索页面,按照关键词搜索,使用Python编写爬虫,自动爬取搜索结果中图书的书名、出版社、价格、作者和图书简介等信息。
数据来源: 当当搜索页面http://search.dangdang.com/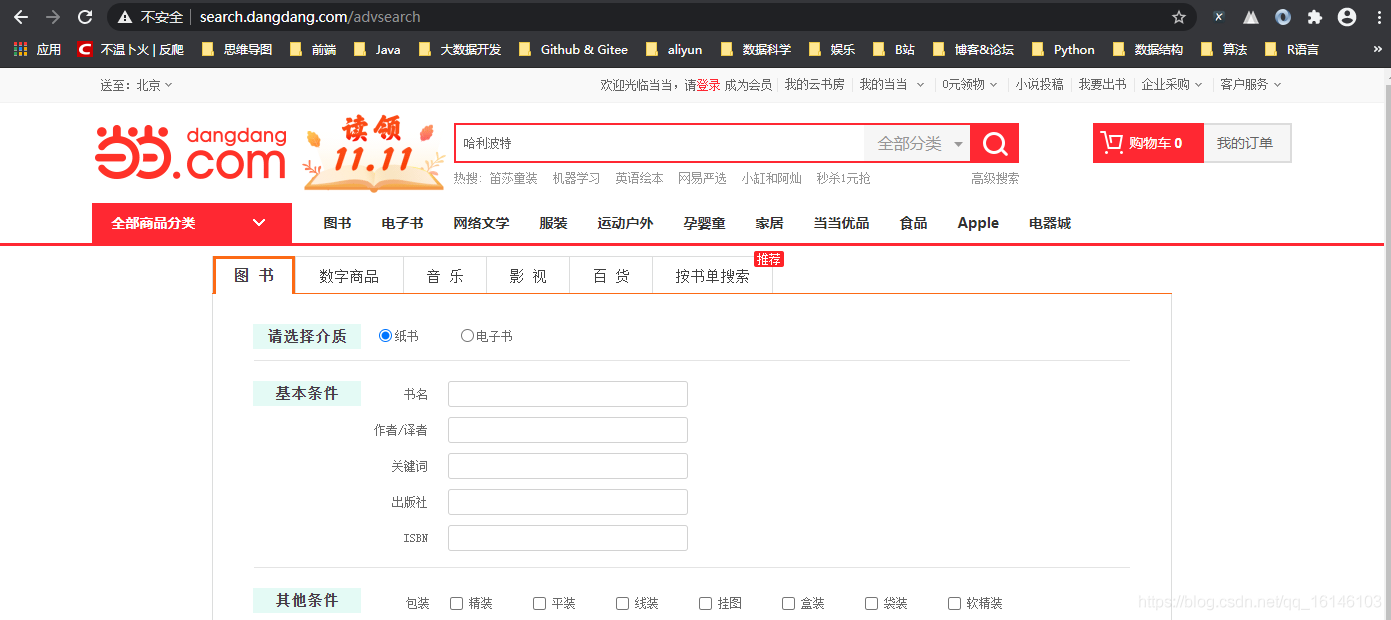
3.2 URL编码与解码
我们先随机输入一个关键词进行搜索,在此我们把机器学习作为关键词。
我们可以看到有乱码,看到这个乱码我们就要知道这是我们输入关键词的URLEncode
下面我们尝试把后面的多余部分删除
http://search.dangdang.com/?key=%BB%FA%C6%F7%D1%A7%CF%B0
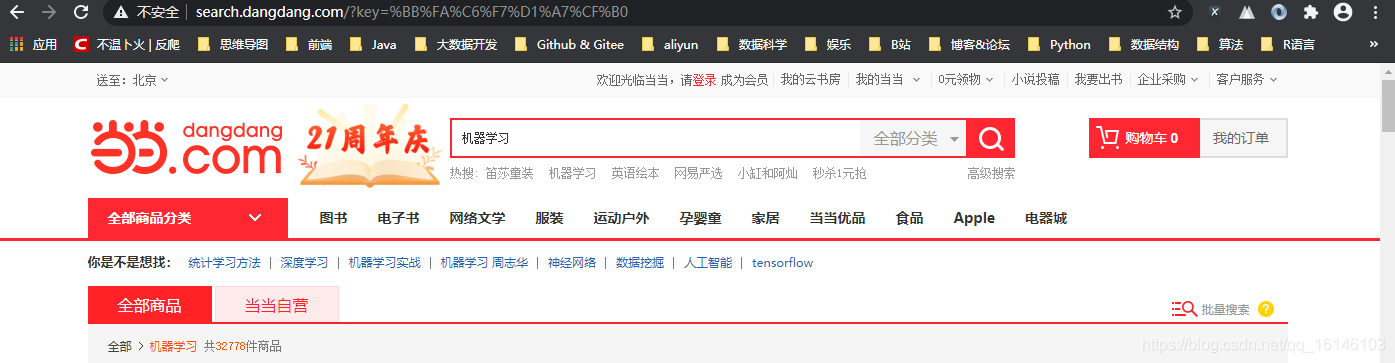
我们发现这个正是我们搜索的URL。我知道各位肯定对URLEncode与URLDecode。
学长在此给出一个在线解码工具:https://tool.chinaz.com/tools/urlencode.aspx
下图中的GIF为演示解码与编码的过程: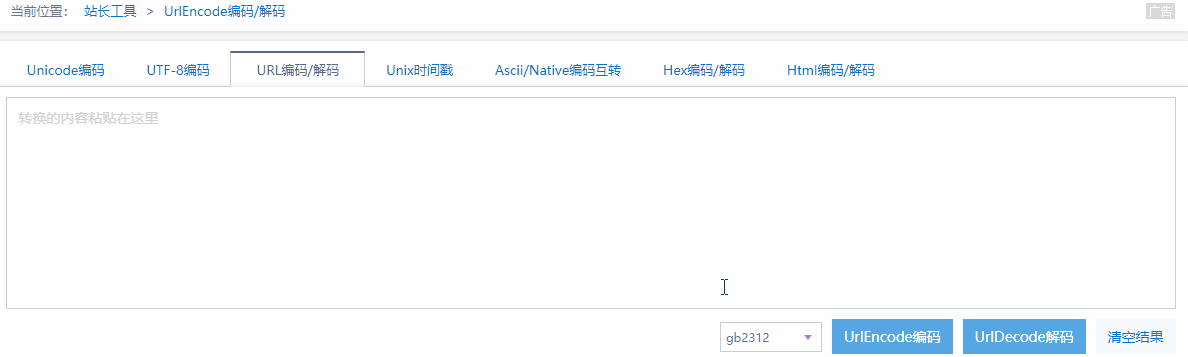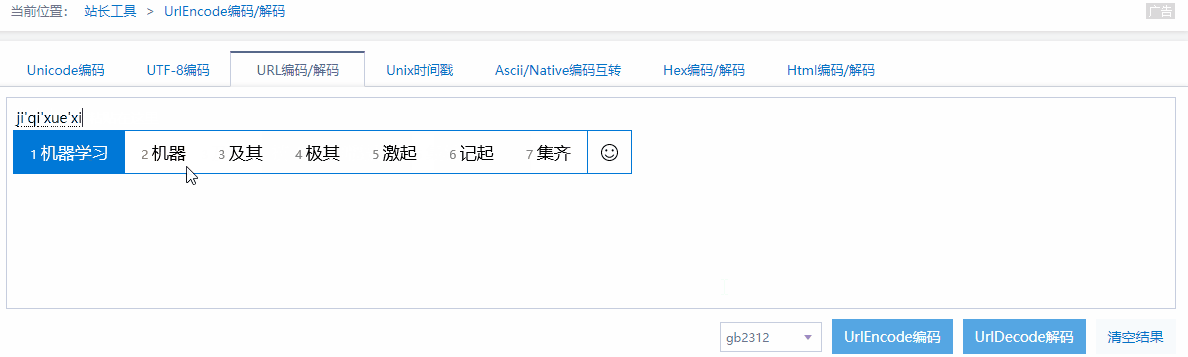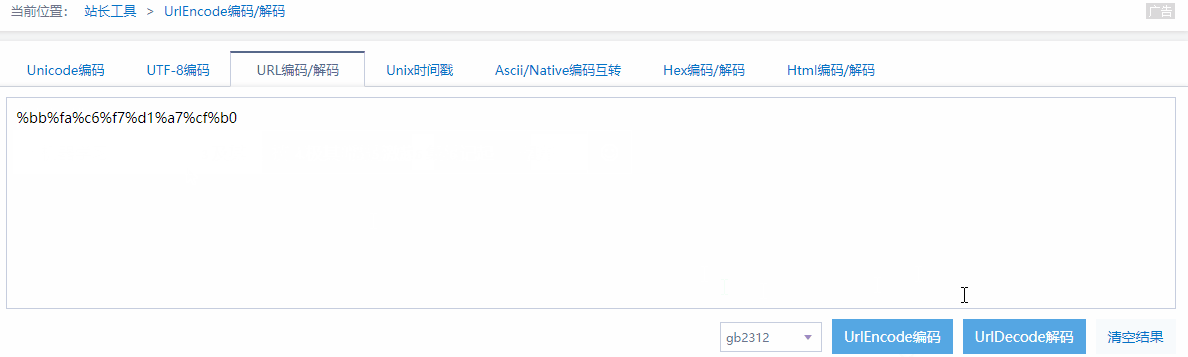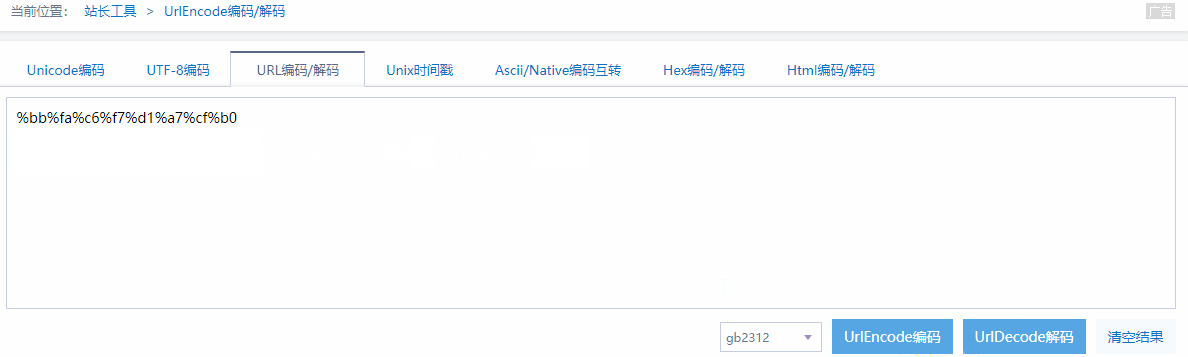
下面我们对比下是不是如此:

经过对比我们发现链接是一样的,那么我们接下来尝试直接输入汉字搜索尝试下
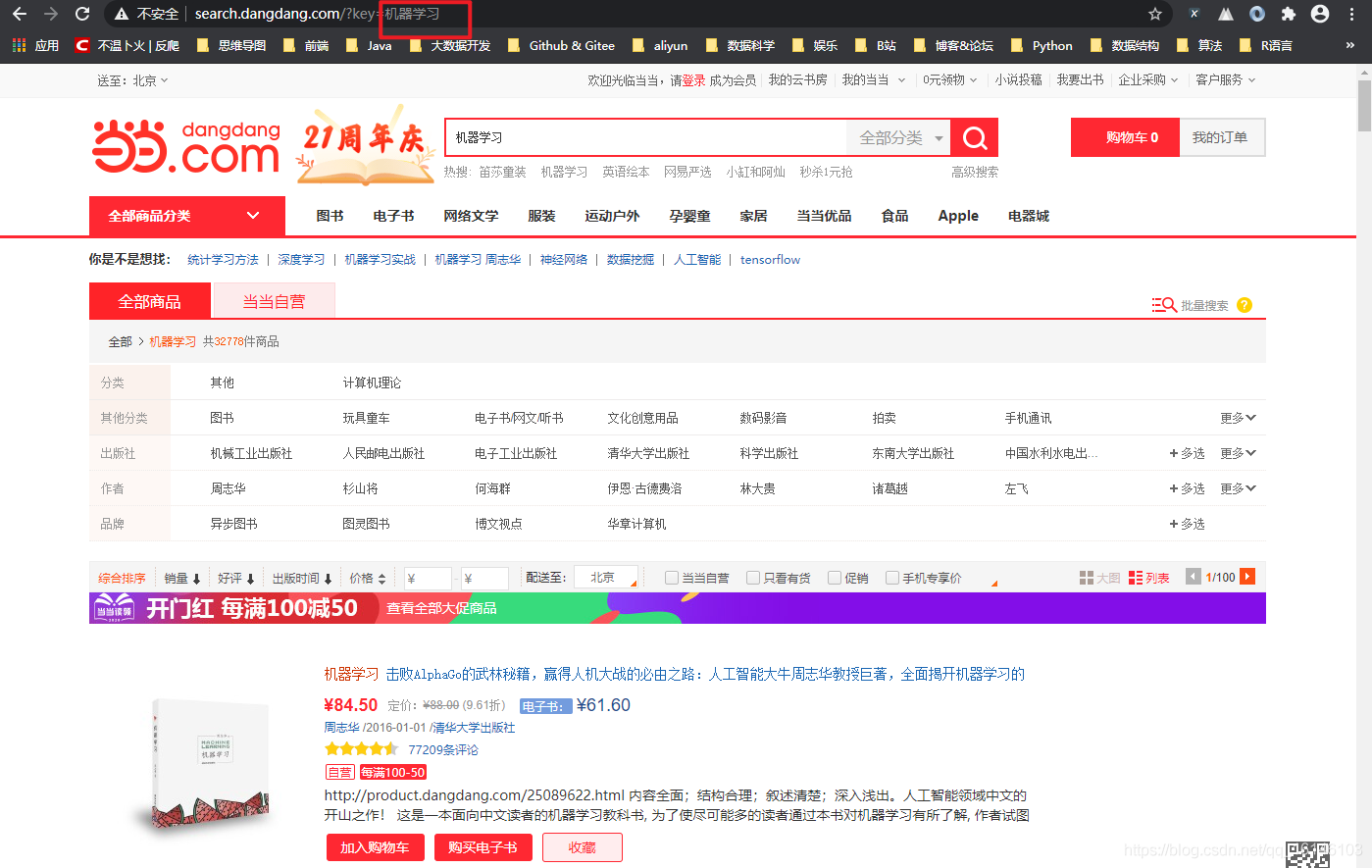
我们发现是可行的,那么我们就可以确定URL链接为:
'http://search.dangdang.com/?key='+ '机器学习'
3.3 单页面图书信息下载
1. 网页下载
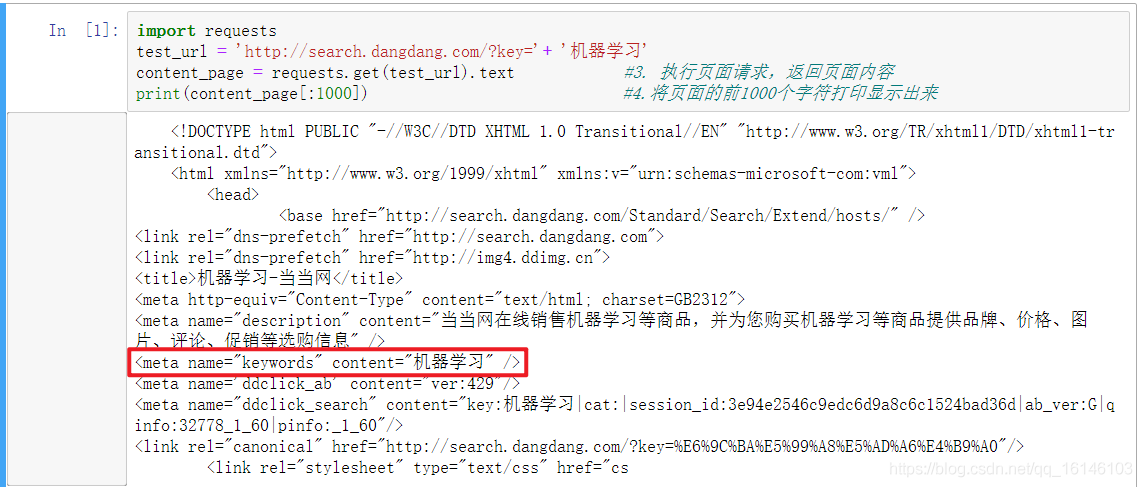
Python中的 requests 库能够自动帮助我们构造向服务器请求资源的request对象,返回服务器资源的response对象。如果仅仅需要返回HTML页面内容,直接调用response的text属性即可。在下面的代码中,我们首先导入requests库,定义当当网的搜索页面的网址,设置搜索关键词为"机器学习"。然后使用 requests.get 方法获取网页内容。最后将网页的前1000个字符打印显示。
import requests test_url = 'http://search.dangdang.com/?key='+ '机器学习' content_page = requests.get(test_url).text #3. 执行页面请求,返回页面内容 print(content_page[:1000]) #4.将页面的前1000个字符打印显示出来
2. 图书内容解析

我们获取整个网页之后,下面就可以开始做页面的解析。
分析的话我们肯定要先从源码进行分析:
这里我使用Chrome浏览器直接打开网址 http://search.dangdang.com/?key=机器学习 。然后选中任意一本图书信息,鼠标右键点击“检查”按钮。不难发现搜索结果中的每一个图书的信息在页面中为<li>标签,如下图所示: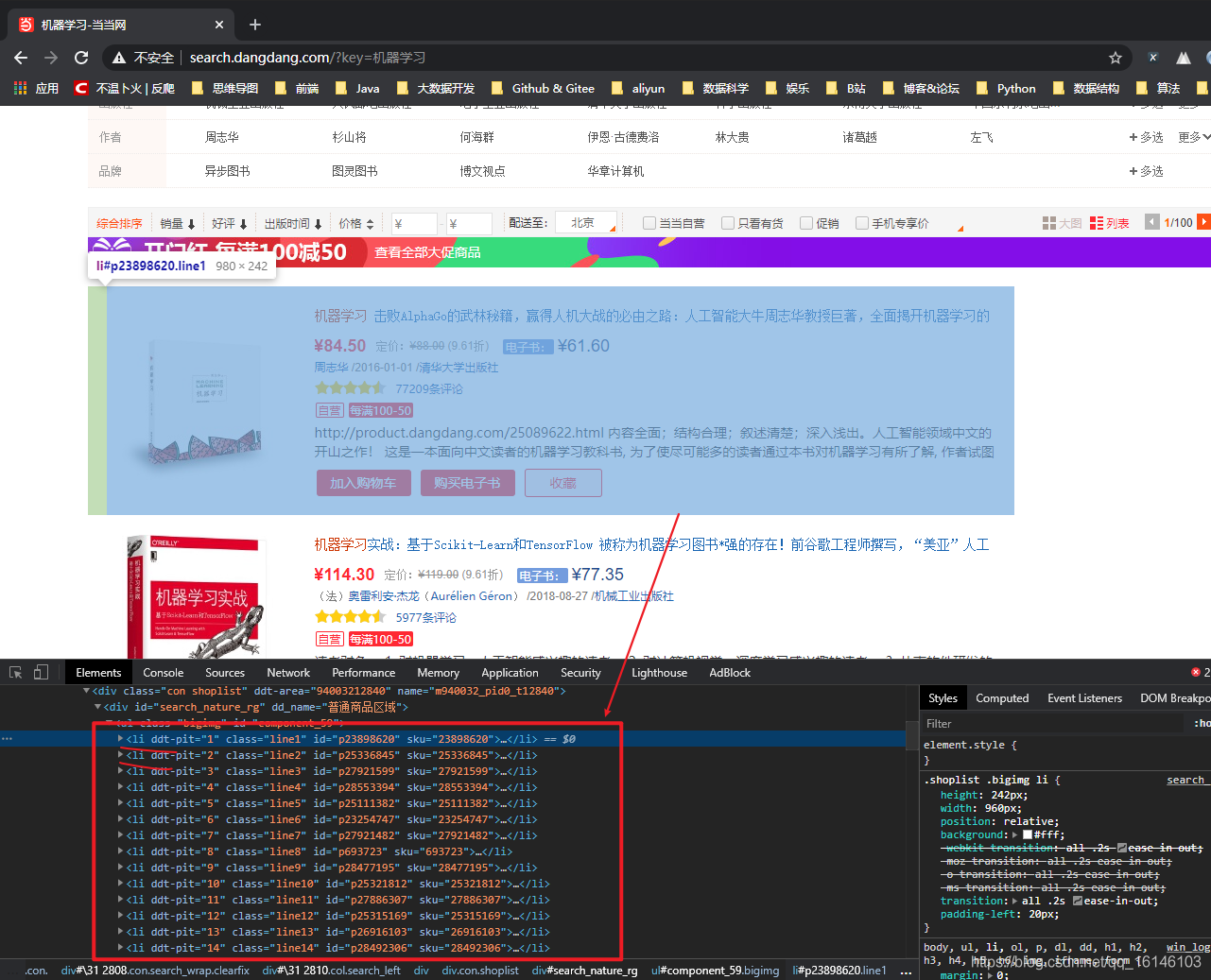
点开第一个<li>标签,发现下面还有几个<p>标签,且class分别为"name"、“detail”、"price"等,这些标签下分别存储了商品的书名、详情、价格等信息。
我们以书名信息的提取为例进行具体说明。点击 <li> 标签下的 class属性为 name 的 <p> 标签,我们发现书名信息保存在一个name属性取值为"itemlist-title"的 <a> 标签的title属性中,如下图所示: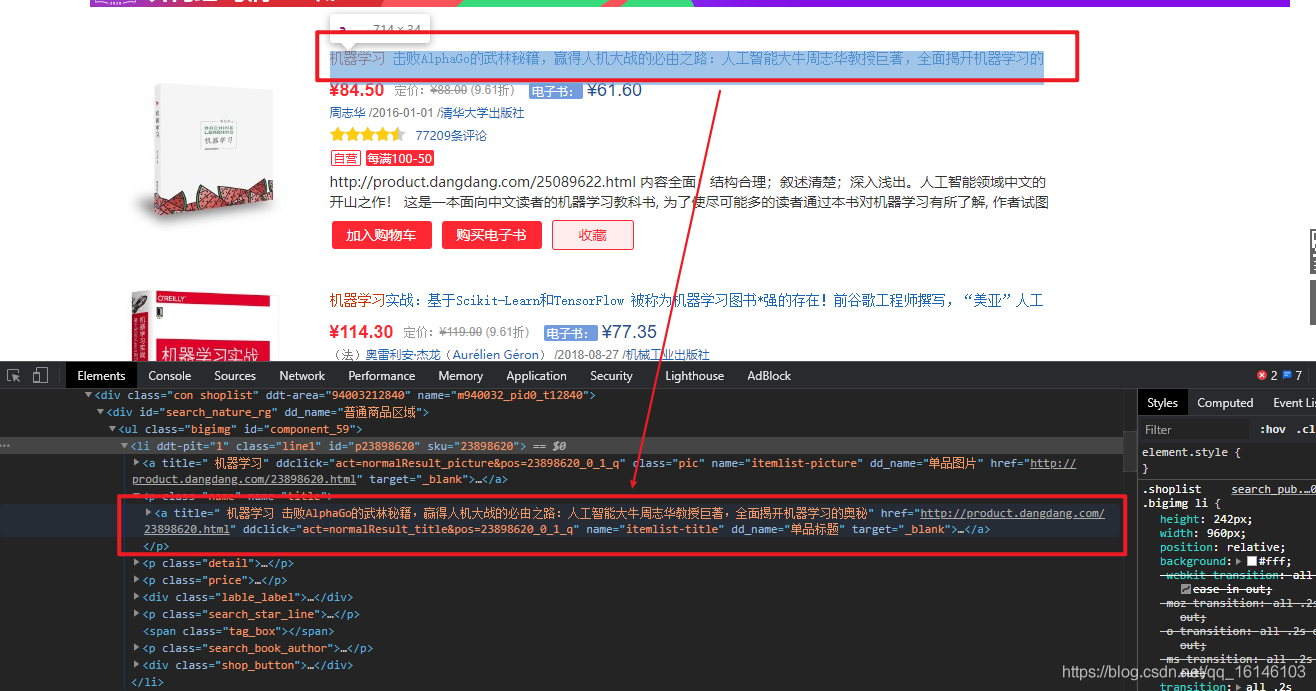
我们可以使用xpath直接描述上述定位信息为 //li/p/a[@name="itemlist-title"]/@title 。下面我们用 lxml 模块来提取页面中的书名信息。xpath的使用在以往的文章中其实已经给出过了,不过现在给出一个比较不错的前端学习网站https://www.w3school.com.cn/xpath/xpath_syntax.asp 。
我们先来看下xpath解析的内容
下面为代码实现:
from lxml import etree page = etree.HTML(content_page) book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') #用xpath提取出书名信息。 book_name[:10] #打印提取出的前10个书名信息

同理,我们可以提取图书的出版信息(作者、出版社、出版时间等),当前价格、星级、评论数等更多的信息。这些信息对应的xpath路径如下表所示。
| 信息项 | xpath路径 |
|---|---|
| 书名 | //li/p/a[@name=“itemlist-title”]/@title |
| 出版信息 | //li/p[@class=“search_book_author”] |
| 当前价格 | //li/p[@class=“price”]/span[@class=“search_now_price”]/text() |
| 星级 | //li/p[@class=“search_star_line”]/span[@class=“search_star_black”]/span/@style |
| 评论数 | //li/p[@class=“search_star_line”]/a[@class=“search_comment_num”]/text() |
由于此部分学长早已经测试过了,因此在此就不再测试了。
下面我们可以编写一个函数content,输入一个页面内容,自动提取出页面包含的所有图书信息。
from lxml import etree def content(content_page): books = [] page = etree.HTML(content_page) book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') #书名 pub_info = page.xpath('//li/p[@class="search_book_author"]')#出版信息 pub_info = [book_pub.xpath('string(.)') for book_pub in pub_info] price_now = page.xpath('//li//span[@class="search_now_price"]/text()')#当前价格 stars = page.xpath('//li/p[@class="search_star_line"]/span[@class="search_star_black"]/span/@style') #星级 comment_num = page.xpath('//li/p[@class="search_star_line"]/a[@class="search_comment_num"]/text()') #评论数 for book in zip(book_name, pub_info, price_now, stars, comment_num): books.append(list(book)) return books books = content(content_page) books[:5]

我们看上图,发现并不是很方便对吧。为了显示的方便,我们将上述提取到的图书信息转换成 Pandas 的 DataFrame 格式。
import pandas as pd books_df = pd.DataFrame(data=books,columns=["书名","出版信息","当前价格","星级","评论数"]) books_df[:10]

3. 图书数据存储
我们已经成功从网页中提取出了图书的信息,并且转换成了 DataFrame 格式。可以选择将这些图书信息保存为 CSV 文件,Excel 文件,也可以保存在数据库中。这里我们使用 DataFrame 提供的 to_csv 方法保存为CSV文件。
books_df.to_csv("./books_test.csv",index=None)
我们测试是没有任何问题的,那么接下来我们可以尝试下载多页图书的信息了。
3.4 多页面图书信息下载
如果先实现多页的话,我们需要观察下搜索页面的翻页。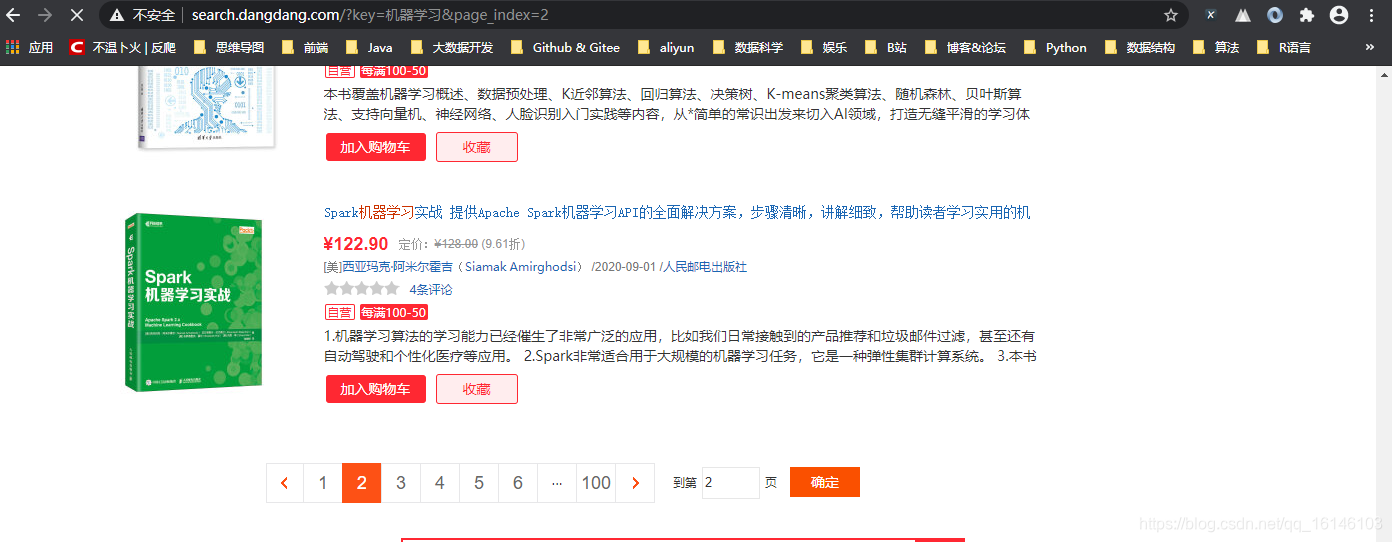
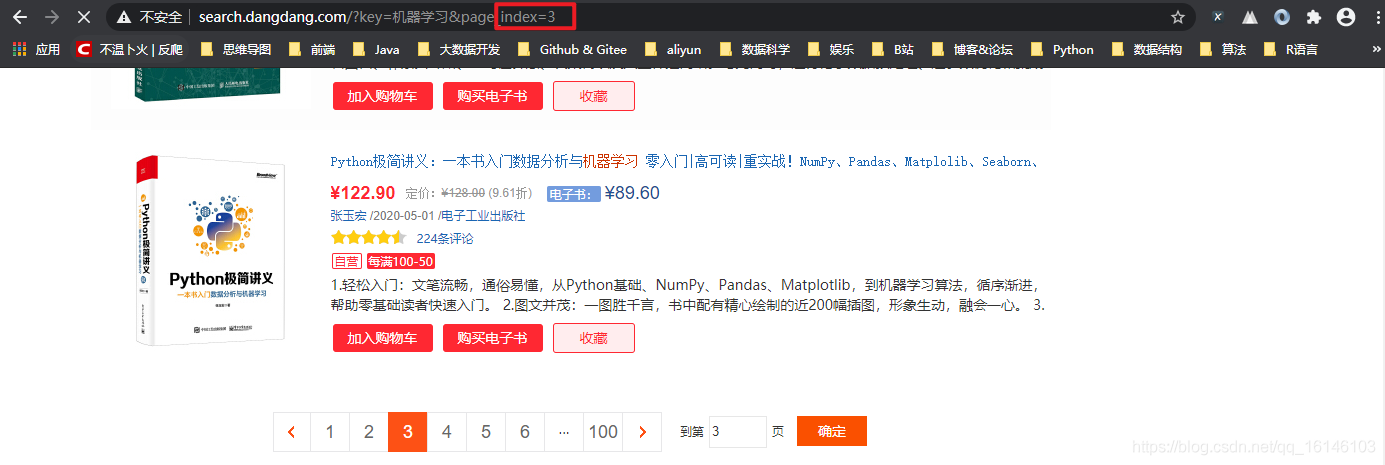
观察搜索页面最底部,输入一个关键词,通常会返回多页结果,点击任意一个页面按钮,然后观察浏览器地址栏的变化。我们发现不同页面通过浏览器URL中添加 page_index 属性即可。例如我们搜索"机器学习"关键词,访问第15页结果,则使用以下URL:
http://search.dangdang.com/?key=机器学习&page_index=15
假设我们一共希望下载15页内容,则可以通过以下代码实现。
import time key_word = "机器学习" #设置搜索关键词 max_page = 15 #需要下载的页数 books_total = [] for page in range(1,max_page+1): url = 'http://search.dangdang.com/?key=' + key_word + "&page_index=" + str(page) #构造URL地址 page_content = requests.get(url).text #下载网页内容 books = content(page_content) #网页图书信息解析 books_total.extend(books) #将当前页面的图书信息添加到结果列表 print("page " + str(page) +", "+ str(len(books)) + " books downloaded." ) time.sleep(10) #停顿10秒再下载下一页
转换成DataFrame格式并随即抽取5个图书显示。
books_total_df = pd.DataFrame(data=books_total, columns=["书名","出版信息","当前价格","星级","评论数"]) books_total_df.sample(5)

将图书信息保存为文件。
books_total_df.to_csv("./books_total.csv",encoding="utf8",sep="\t",index=None)
四、数据清洗
在数据清洗之前我们需要查看一下原数据。
4.1 读取数据
首先,我们借助 Pandas 包提供的 read_csv 方法读取原始数据,将其转换成 Pandas 中的 DataFrame 格式。注意由于数据中包含中文,需要正确设置字符编码。
import pandas as pd data = pd.read_csv('./books_total.csv',encoding="utf8",sep="\t")
在查看之前最好先通过 shape 属性可以查看数据的行数和列数。
data.shape

查看数据的前5行。
# 括号内不写 一般都默认为5 data.head()

通过观察,我们可以看到原始数据中有许多问题,例如当前价格带有人民币符号’¥’,评论数含有文本等等。在本demo中我们按照步骤完成数据清洗,主要任务为:
-
1)去掉当前价格这一列中的 ‘¥’ 符号,转换成数值格式。
-
2) 星级列转换成数字格式,取值范围为{0, 0.5, 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5,5}。例如width:90%先转换为0.9,然后以最高星分数5乘以0.9最终得到4.5。
-
3)对于评论数这一列直接提取数值。
-
4)出版信息分为三列分别是作者、出版日期、出版社。
-
5)将原始数据中的书名拆分为为书名和简介两列。
4.2 提取价格数值
首先我们处理价格、星级、评论数,这几个比较简单,对于价格最主要的目的是提取数据中的数值,但真实数据除了数值还包含其他的内容,我们可以使用正则匹配将数值提取出来。
正则表达式的话,其实学长之前已经介绍过了,不过现在再次用到。那么学长就再简单的介绍下吧!
正则表达式是一种按照特定规则搜索文本的方法。在正则表达式中\d表示数字,+表示匹配前一个字符1次或无限次,常见的正则表达式符号含义见下表所示。
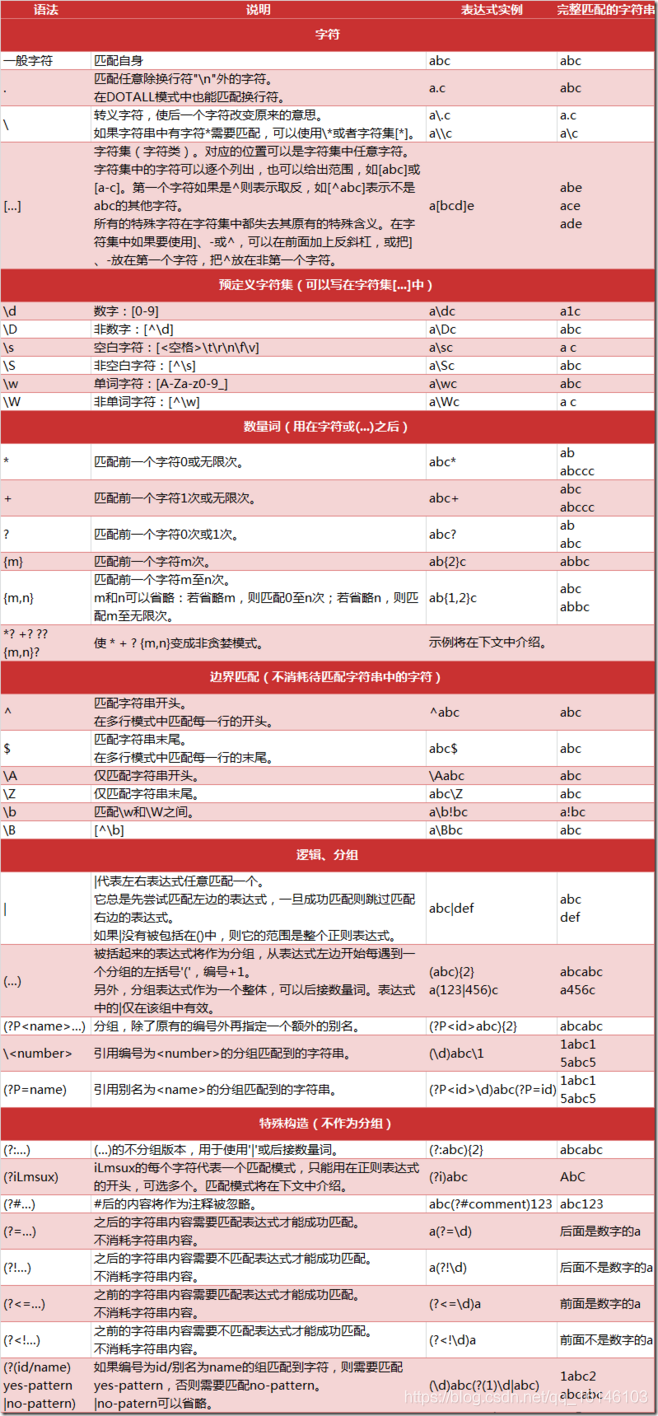
上图是不是比较多,所以学长在百科上找到了另一个合集: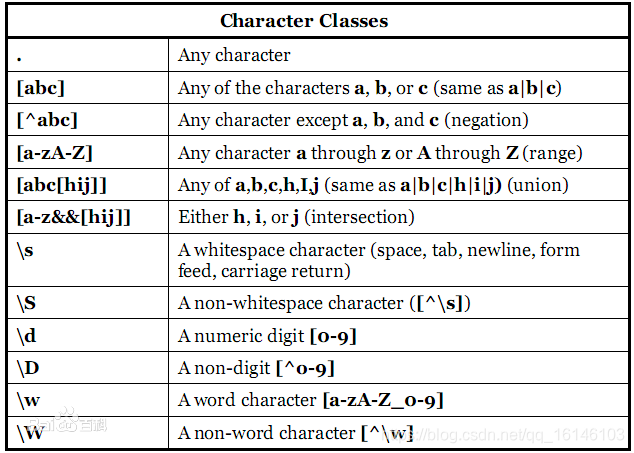
在Python中,re 包实现了正则表达式的匹配,常用的 search 函数能够完成匹配。下面我们编写 get_numers 函数用来提取一个字符串中的数值。
import re #导入 re 包 def get_numers(x): regex_num = "\d{1,4}\.{0,1}\d{0,2}" #编写匹配数字的正则表达式 return float(re.search(regex_num,x)[0]) # 调用 re.search 函数进行匹配 get_numers("¥84.00")

使用DataFrame的map方法可对当前价格这一列的每一个数据遍历执行,并取代原来的列。
data['当前价格'] = data['当前价格'].map(get_numers) data.head()

现在我们可以看出价格这一列的数值已经全部清洗出来了。
4.3 提取评论数
由于评论是也是提取数值,因此对于评论数使用同样的方法处理,具体如下。
data['评论数'] = data['评论数'].map(get_numers) data.head()

可以看到评论数这一列的数值是float类型,我们需要将其转换成int类型。
data["评论数"] = data["评论数"].astype("int") data["评论数"] .head()

4.4 转换星级
对于星级,首先要提取出数值,然后对数值进行计算,计算方法为用提取后的数值除以20,就得到最终的星级。对应关系如下表:
| 原始数据 | 数值 | 星级 |
|---|---|---|
| width: 0%; | 0 | 0 |
| width: 10%; | 10 | 0.5 |
| width: 20%; | 20 | 1 |
| width: 30%; | 30 | 1.5 |
| width: 40%; | 40 | 2 |
| width: 50%; | 50 | 2.5 |
| width: 60%; | 60 | 3 |
| width: 70%; | 70 | 3.5 |
| width: 80%; | 80 | 4 |
| width: 90%; | 90 | 4.5 |
| width: 100%; | 100 | 5 |
这个时候,我们就可以写出如下代码:
data['星级'] = data['星级'].map(get_numers)/20 data.head()

4.5 获取出版信息
接下来我们处理出版信息这一列,从原始数据中可以看到,这一列主要包含三个信息,分别是作者、出版日期、出版社。它们以/分隔,并且存放在一个数据单元中,因此我们将它们分别取出,然后单独存为三列。
1. 提取作者
从原始数据中可以看出以/分隔的第一个数据是作者,因此我们可以直接提取。
使用字符串的split方法可以对字符串按照特定字符分割,并且分割后是列表形式,
例如:
test = '周志华/2016-01-01/清华大学出版社' test.split('/')

对出版信息这一列的每一个数据按照/分隔后取第一个数据就是作者,提取后我们将它保存在作者这一列。
data['作者'] = data['出版信息'].map(lambda x:x.split('/')[0]) data.head()
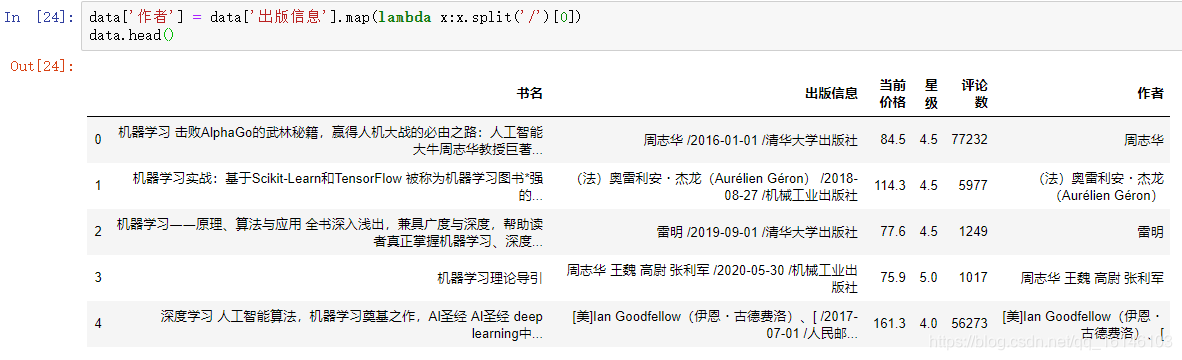
我们可以看到作者已经提取出来。
2. 提取出版社
采样正则表达式匹配出版社信息,正则表达式为 (\S{1,10}出版社) 。下面我们实现 get_publisher 函数,从出版信息列找那个提取出版社信息。
def get_publisher(x): regex_pub = "/(\S{1,10}出版社)" pub_match_result = re.search(regex_pub,x) if pub_match_result != None: return pub_match_result[1].strip() else: return "" get_publisher("周志华王魏高尉张利军/2020-05-30/机械工业出版社")

在数据中新增 出版社 一列。
data['出版社'] = data['出版信息'].map(get_publisher) data['出版社'].sample(10)

如上所示,我们成功地提取了每个数据的出版社。
3. 提取出版日期
出版日期的格式为 YYYY-MM-DD ,对应的正则表达式为 (\d{4}-\d{2}-\d{2}) 。
def get_pubdate(x): regex_date = "/(\d{4}-\d{2}-\d{2})" pubdate_match_result = re.search(regex_date,x) if pubdate_match_result != None: return pubdate_match_result[1].strip() else: return "" get_pubdate("周志华王魏高尉张利军/2020-05-30/机械工业出版社")

新增 出版日期 列,并借助 pd.to_datetime 方法将字符串格式的时间转换成时间格式。
data['出版日期'] = pd.to_datetime( data['出版信息'].map(get_pubdate)) data['出版日期'] .sample(10)

如上所示,我们已经成功提取作者、出版社、出版日期,因此原始的出版信息这一列可以删除。
del data["出版信息"] data.head()
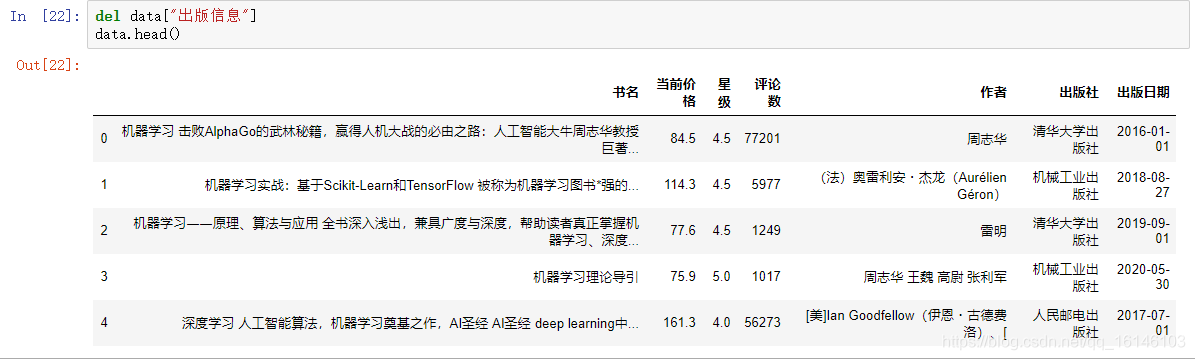
观察数据后发现,此时已经没有出版信息这一列,说明我们已经删除成功,现在只剩下书名这一列需要处理。
4.6 提取书名和书简介
书名信息中混合这书的简介信息,观察原始数据中书名一列,能找到一些规律。除去最开始可能包含的一些包含在 【】和 [] 中间的标注信息,剩余的内容中书名和其他内容基本是由空格隔开的。所以我们首先将【】和 [] 去掉,然后按照空格分隔字符串,第一个内容便是书名。实现方法如下:
def get_book_name(x): x = x.strip() x = re.sub("【.*?】","",x) x = re.sub("\[.*?\]","",x) return x.split(" ")[0] get_book_name("【全2册】机器学习 周志华著+机器学习与应用 雷明著 全新正版 2本书")

data["书名称"] = data["书名"].map(get_book_name) data.sample(10)
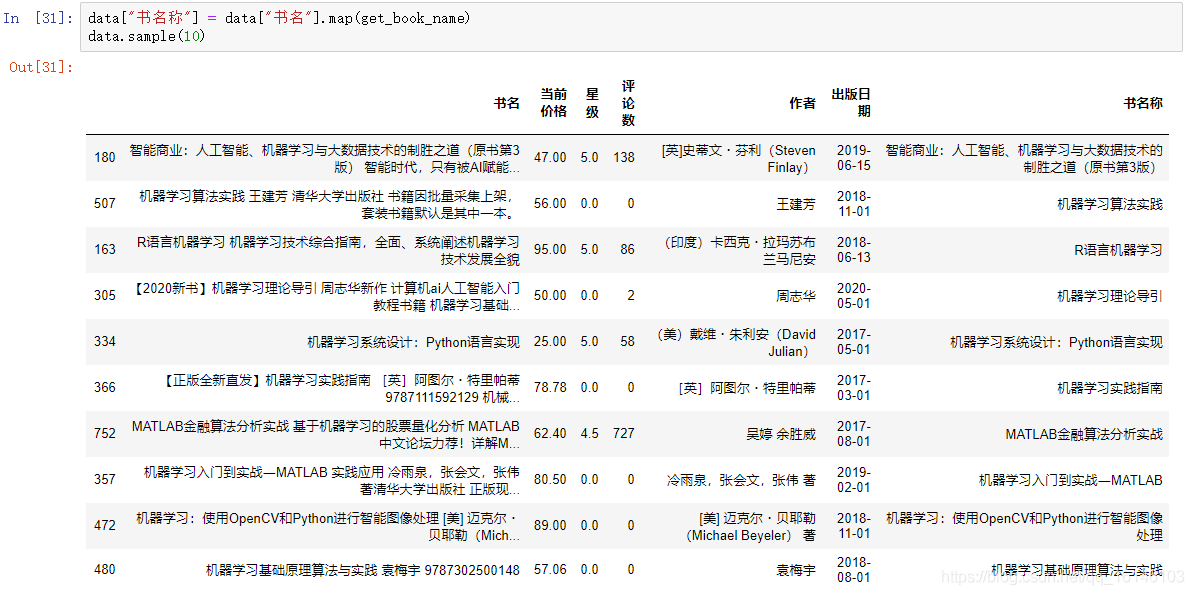
得到书名后,剩余的内容便是简介。
data["简介"] = data["书名"].map(lambda x:x.replace(get_book_name(x),"")) data.sample(5)
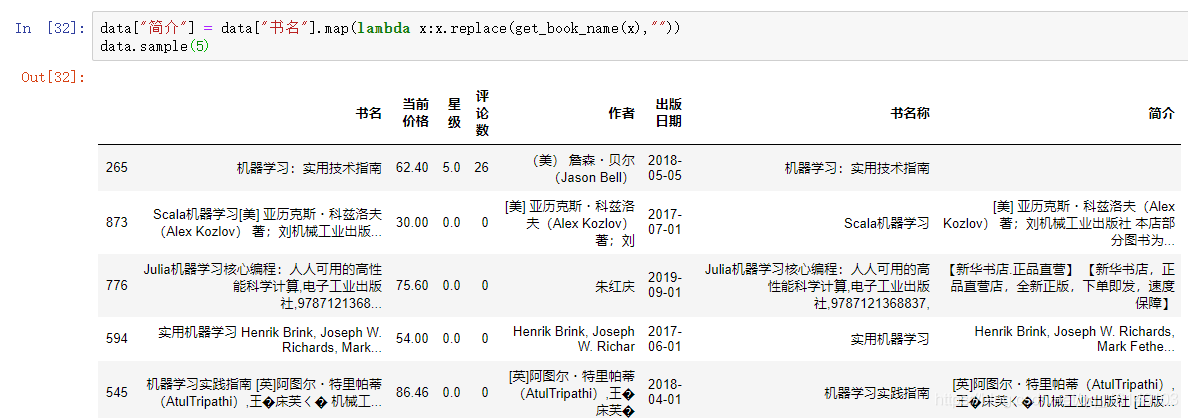
提取出书名称和简介信息后,我们可以将数据中的原始书名列删除。
del data["书名"] data.head()
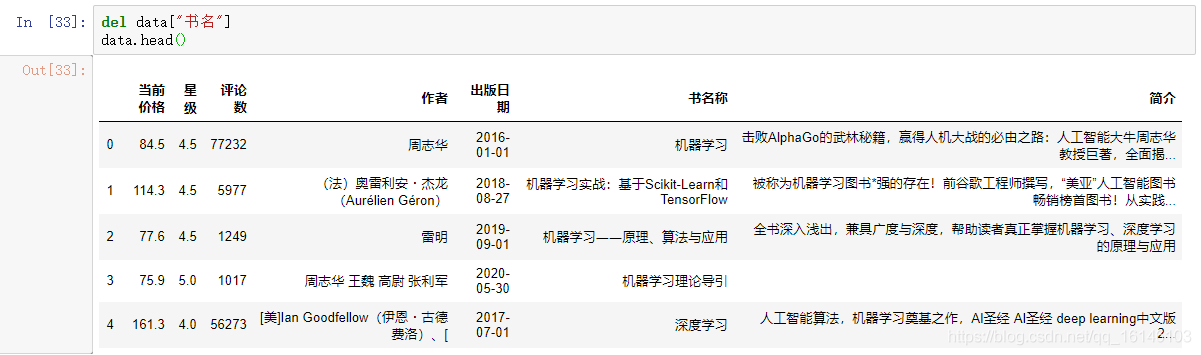
最后,将清洗完成的数据保存到 CSV 文件中。
data.to_csv("./books_cleaned.csv", index="None", sep="\t",encoding="utf8")
五、总结
由于数据采集时获得的数据可能并不规范,不能直接用来分析,因此需要做数据清洗。所以学长我对爬虫抓取的书籍数据进行清洗,主要使用正则匹配和自定义的方法实现。首先提取了价格、评论以及星级的数值;然后对于出版信息中的数据分别获取书籍的作者、出版社和出版日期;最后基于原始数据的书名,进一步提取书的简介和名称,相较于前几步来说,提取书简介和书名可能相对复杂一些,当然在实际数据清洗时可能有多种方法,本demo仅提供其中一种方法供大家参考。

美好的日子总是短暂的,虽然还想继续与大家畅谈,但是本篇博文到此已经结束了,如果还嫌不够过瘾,不用担心,我们下篇见!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!


本文转自 https://buwenbuhuo.blog.csdn.net/article/details/109287391,如有侵权,请联系删除。
