







一、画像系统命中接口相关简介
什么是画像系统
标签画像系统是一种数据管理和分析工具,它通过整合和分析用户的行为数据、交易数据、社交数据等多维度信息,构建出用户的详细画像,帮助咱们运营人员更好地理解目标用户群体,从而实现精准营销和精细化运营。
提供了那些能力:标签注册,标签沉淀,标签取值;群体圈选;群体服务(群体命中,群体下载和订阅等 ) 核心能力
怎么实现精准营销和精细化运营
命中接口:它作为连接用户数据和营销活动的桥梁,确保了营销信息能够准确地传递给最合适的用户群体。
业务场景
▪场景一:商城收银台页面,优惠券展示与否,以及优惠金额多少。
▪场景二:金融APP端资源位,展示哪种营销活动。
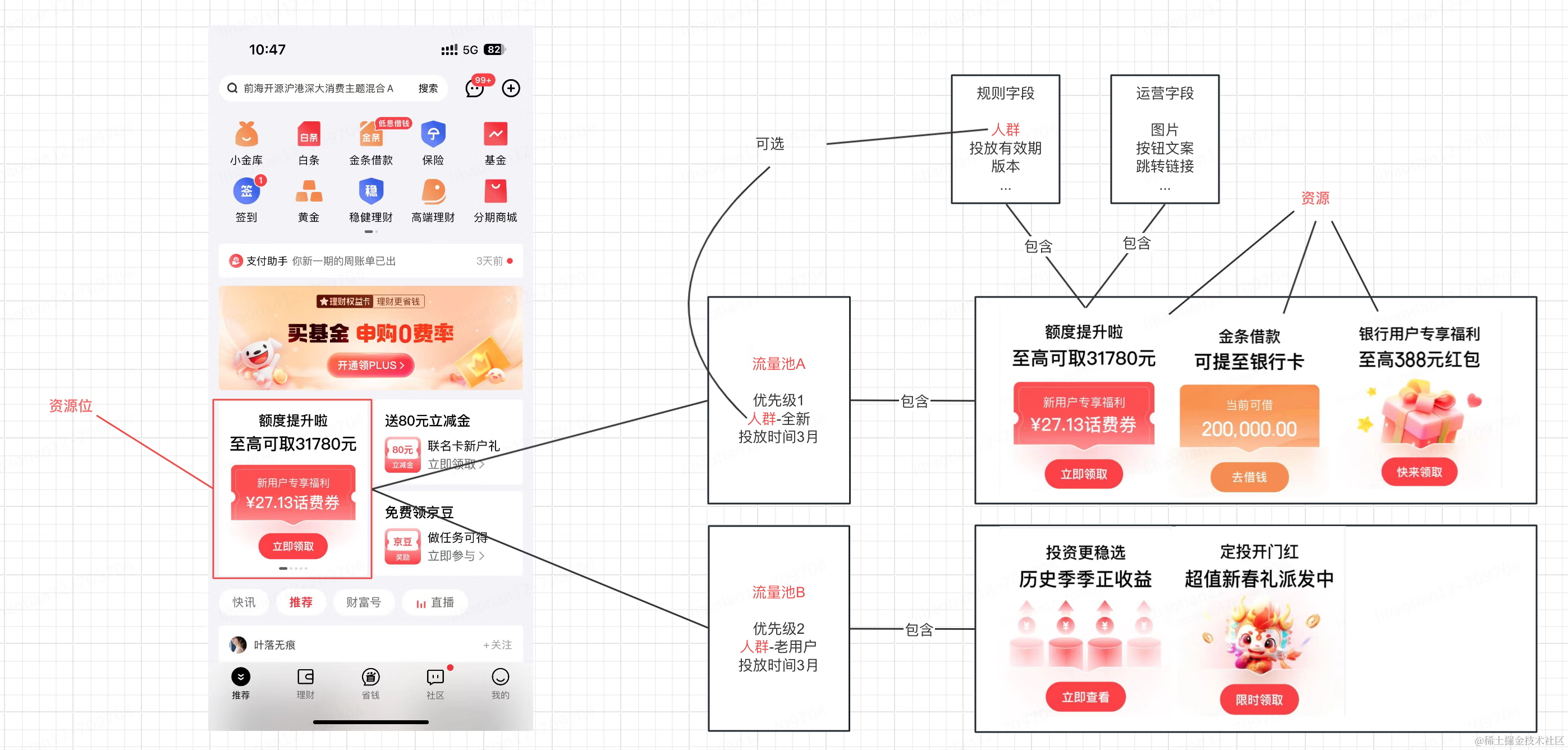
•……
在支付、消金、财富等核心业务中发挥着至关重要的作用,影响着用户拉新、交易转化、促活等关键环节。
命中接口实现逻辑

挑战
•如何保证三高:高性能(50ms以下),高并发(百万级TPS),高可用。
•数据量大:群体数量多,而且大量的群体的pin数量都是千万级别以上,甚至有的群体pin数量达到了数十亿。
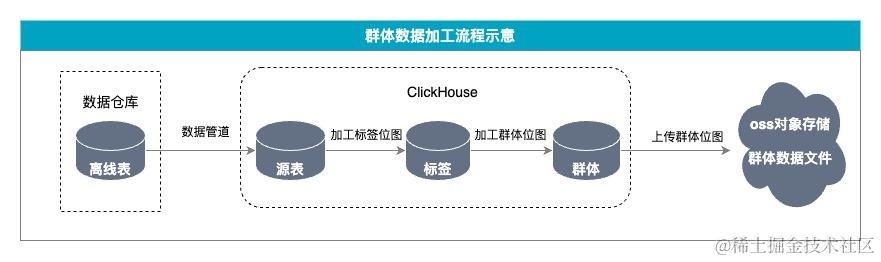

二、画像系统1.0和2.0版本的命中接口
存储方式(物理机内存)
将人群数据从OSS拉取并存储在物理机(32C256G)中,由于群体数量过多,256G不足以将所有的群体的OSS文件都保存下来,所以采用分片的逻辑,每个分片只存储群体OSS文件的四分之一。
方案优缺点
优点:
1、性能达标:基于内存取值,减少中间件依赖, 单机压测到30000TPS,TP999最高40ms;
2、存储成本较低:在当时,和直接使用缓存相比,成本较低;
3、缓解了CK的压力:从OSS拉取文件,减少了CK查询次数。
缺点:
1、初始化群体非常慢: 由于数据是存在机器内存中,每次启动机器总要全量加载所有群体,但随着业务发展,群体数量的增加重启也会越来越慢;
2、扩容成本高:虽然分组内可以水平扩容,但是固定分组后,单机器的内存有限,一旦达到上限需要扩容分组时,必须成倍的扩容,导致扩容分组困难;
3、排查问题效率低:由于是自研的依赖于机器内存的存储方案,整体结构复杂,在运维的能力方面偏弱,运维的相关工具少。
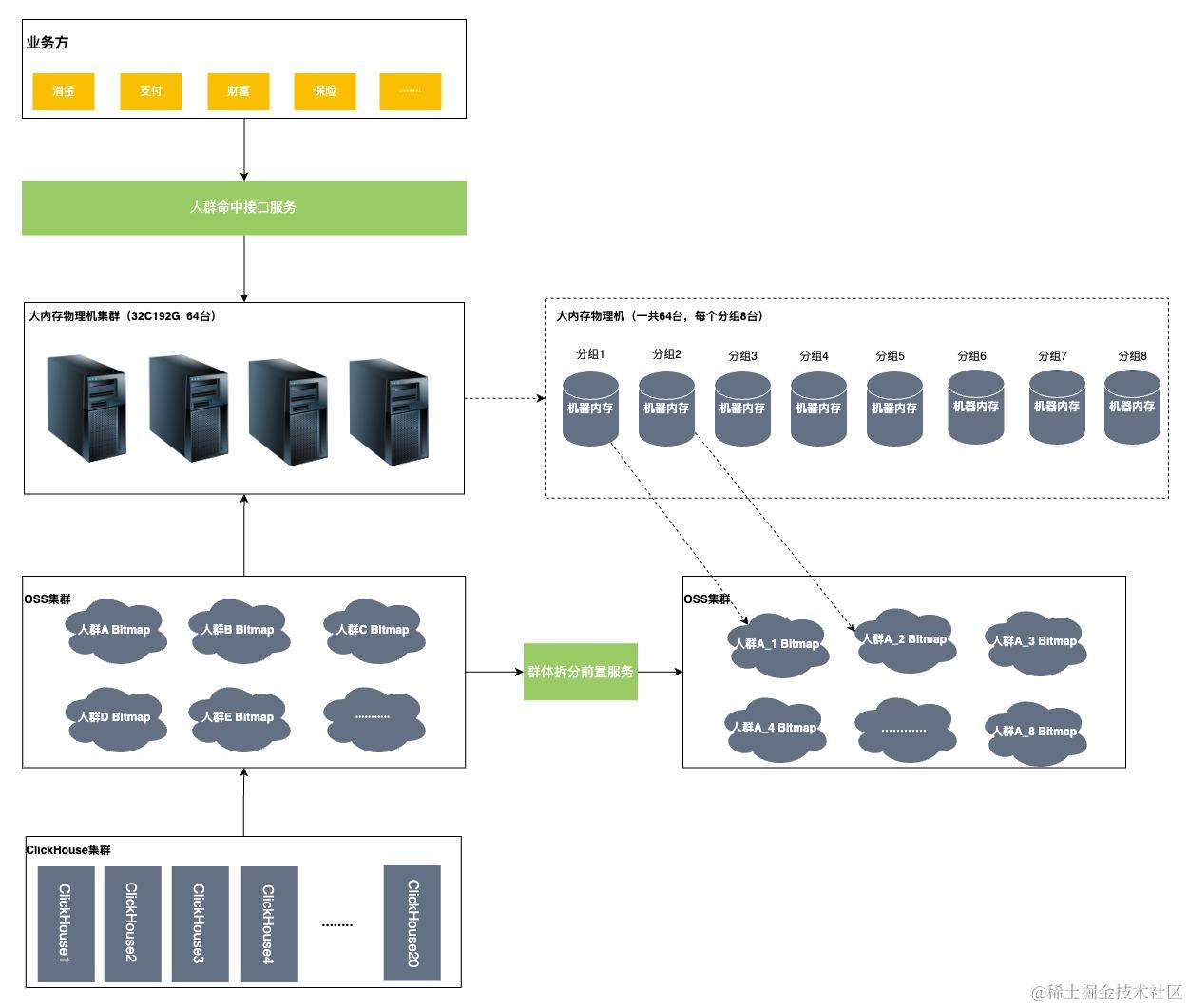
三、画像系统3.0版本的命中接口
背景
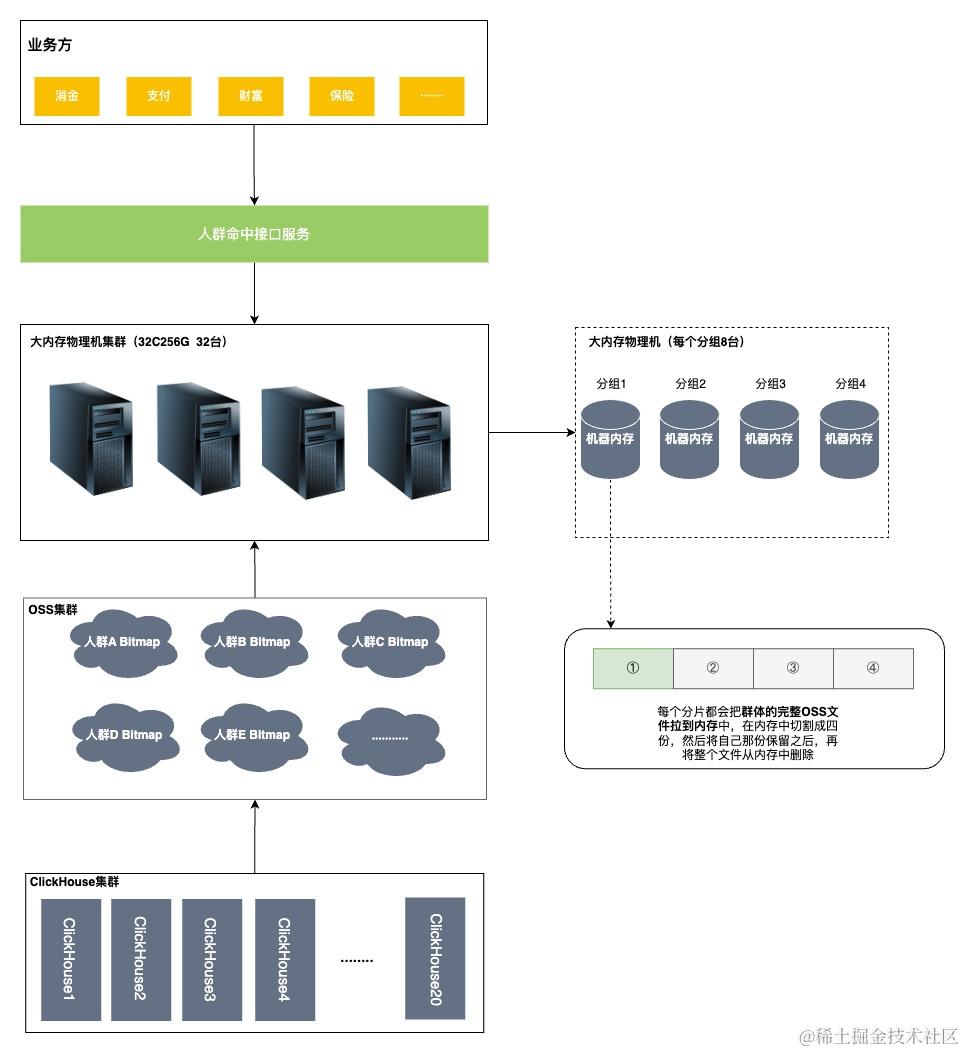
•迁移到了JDOS,JDOS没有256G内存的物理机,所以我们采用的是192G内存的物理机。
•群体数量由8000+群体膨胀到25000+群体, 由于1.0和2.0版本的四分片物理机存储的数据越来越多,快到物理机内存的极限了。
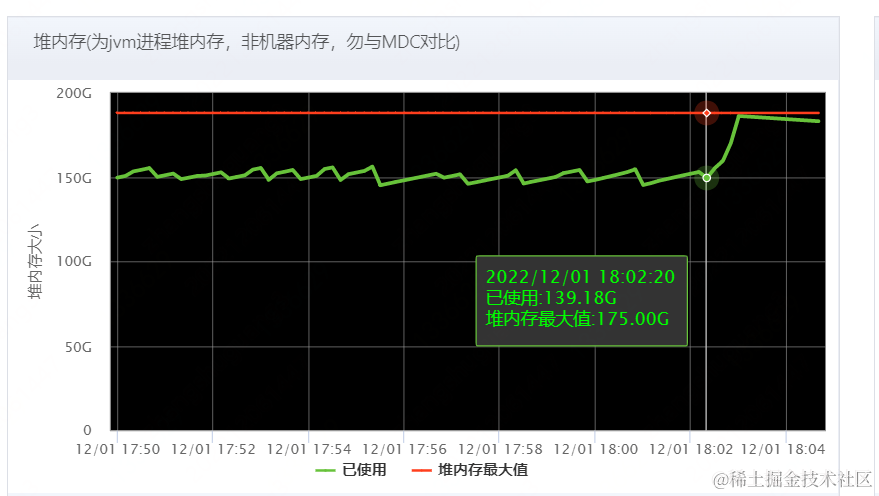
•从OSS拉取群体的时候,会由于网络抖动,导致拉取人群信息有不完整就断掉的情况,会造成重复拉取,导致物理机堆内存抖动,不稳定,影响TP999,影响业务正常进行。
存储方式(物理机内存)
依旧将人群数据存储在物理机中,但使用了拆分前置的操作,并且将原先的物理机四份片改为了八分片。先将群体的OSS文件拆分成8分,然后物理机对应的分片只需要去拉取自己分片对应的文件即可。
数据分层方案(缓存)
为什么需要使用缓存做数据分层
•提高系统的可用性和可靠性: 应对不可预测的故障 ,网络问题,服务器故障等, 数据分层策略可以帮助系统应对这些不可预测的故障,提高系统的可用性和可靠性
存储方式
因为set集合的特征,元素小于512个会自动压缩,所以我们使用set集合来存用户的offset的。
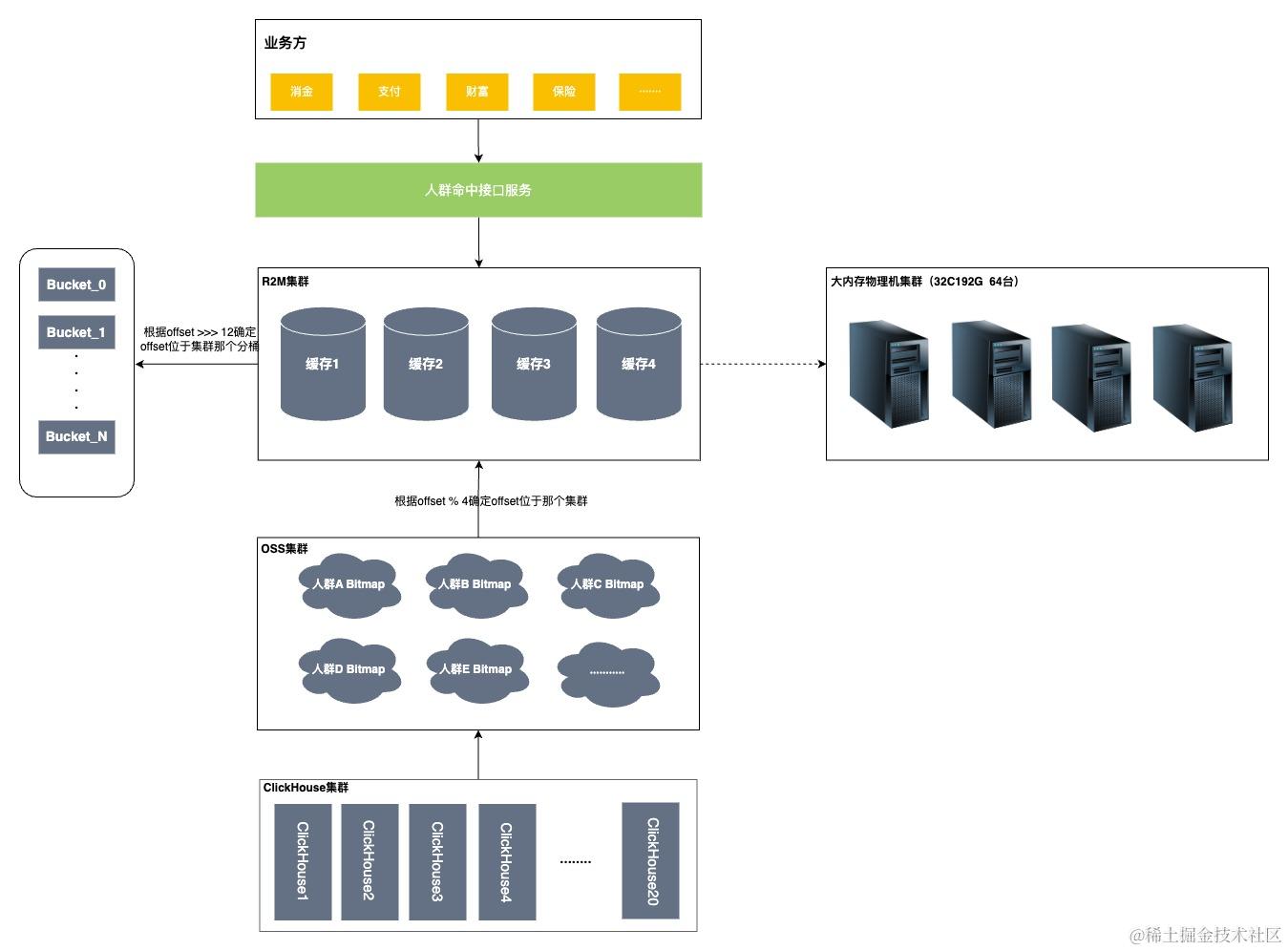
四、画像系统4.0版本的命中接口
背景
由于在3.0的时候,offset的编码已经超过了2的32次方。我们使用的ck版本加工群体位图的时候不支持大于2的32次方位图计算,升级版本不兼容。对ck计算层架构升级:小于32位的offset计算到现有的bitmap中,大于32位的offset计算时,所有offset - 2^32,计算到高32位bitmap。基于这点想到了如果低成本使用R2M。也可以通过开发达到RoaringBitmap的压缩效果。
为什么要压缩
我们知道创建Bitmap的时候,长度必须是最大的offset的长度。再结合我们的场景,我们现在的pin数量已经超过了数十亿,但是每个人群不可能都是数十亿之多,所以我们位图存储的数据不是连续的,而是稀疏的。
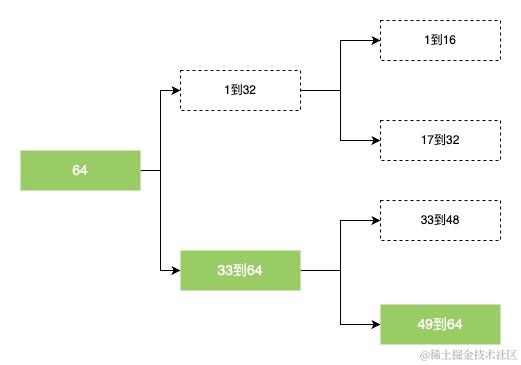
假设我们现在只有64个用户,然后有一个人群包,只有1个offset,63。
按照正常我们需要创建一个64位的Bitmap
| 1 | 2 | 3 | …… | 63 | 64 |
|---|---|---|---|---|---|
| 0 | 0 | 0 | …… | 1 | 0 |
这时候我们就把数组拆分成2组,1到32的用户存储到第1组,把33到64的用户存储到第二组。此时我们发现第一组的数组里全是0,那第一组是不是可以不创建?这样我们就用一个32位大小的数组存储了64位的数据。
接下来更进一步,把64位的数组拆成每16个一组,那么我们只需要创建最后一个分组的数组,也就是16位的数组来达到进一步压缩的目的。
| 49 | 50 | 51 | …… | 63 | 64 |
|---|---|---|---|---|---|
| 0 | 0 | 0 | …… | 1 | 0 |
压缩流程
根据我们的业务场景,每个位图大小是65536压缩效果最好。
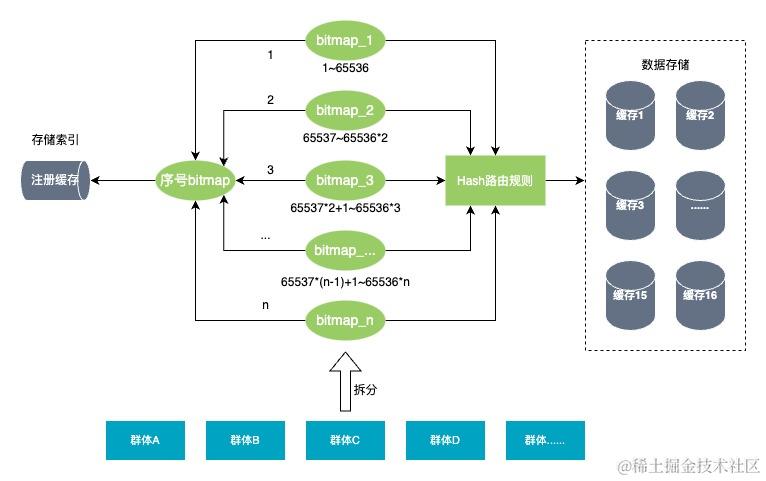
存储方式(缓存)
部署多个R2M集群(或分组),将群体bitmap进行拆分,并根据一定的路由策略存储到不同的集群上,通过不同的集群提供查询能力,如下图
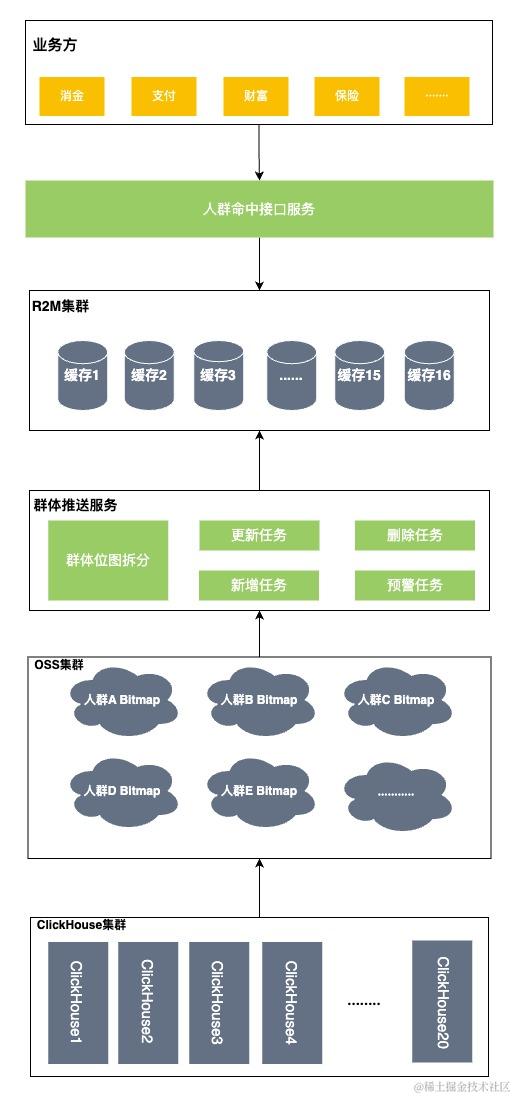
在新方案中,增加了一整套的群体推送服务,包括数据的新增,更新,删除,检测,重试等全部可视化到页面,大大增强了群体加载的可监测性及有效性,而在之前的方案中,非常缺少这些有效的运维手段。

流程对比
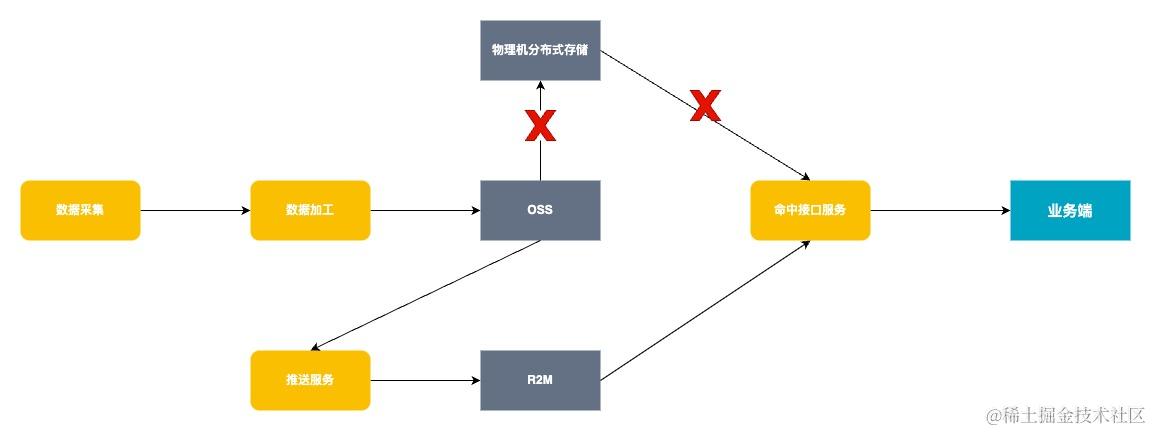
采用集中缓存替换自研分布式存储优缺点对比
| 自研分布式存储 | R2M存储(新方案) | |
|---|---|---|
| 劣势 | 优势 | |
| 稳定性 | ·突然新增的大量人群信息新增或变更,堆内存变化比较剧烈,容易达到服务器上限 ·恢复周期长:服务器出现宕机后,恢复周期较长 ·单分片比较大,单台命中存储服务的流量占比比较大,出现故障时,影响比较大**** | ·R2M具有自动扩容的能力,当达到了一定的使用比例,分片会自动扩容 ·分片出现宕机,会主从切换,瞬间恢复,并且支持异地机房备份 ·单分片比较小,影响范围更小 |
| 维护成本 | ·启动慢:单台存储服务启动比较慢,启动最长达到30分钟 ·上线难:总共有103台服务器,65个分组(8个预发分组,57个生产分组),分组管理比较复杂,配置文件比较难以管理,启动要注意的事项比较多 ·扩容难:由于各分组是有状态的,并且要求均是特殊的物理机,扩容相对复杂**** | ·没有这个节点了,不存在启动慢,上线难问题 ·扩容简单:自动扩容或者提扩容工单即可 ·缓存集群由运维团队在维护,他们有专业的团队和工具维护**** |
| 硬件成本 | ·总共103台物理机服务器,其中预发服务器 8台,命中服务器48台,下载服务器8台,其他39台(待下线)--32C192G服务器 | ·R2M是科技集群,碎片会更小有的管理和使用,可以更有效的使用缓存空间 ·不存在预发的服务器一直在在浪费 ·40亿集群大概500M,如果是13000个平均是10个亿的人群,大概是1.5T,主从结构大概就是3T,换算成成192G的物理,大概就是15台物理机,如果保持水位是60%的话,大概物理机是25台物理机**** |
| 其他 | ·只在初始化时拉取一次OSS文件即可,减少带宽占用 |
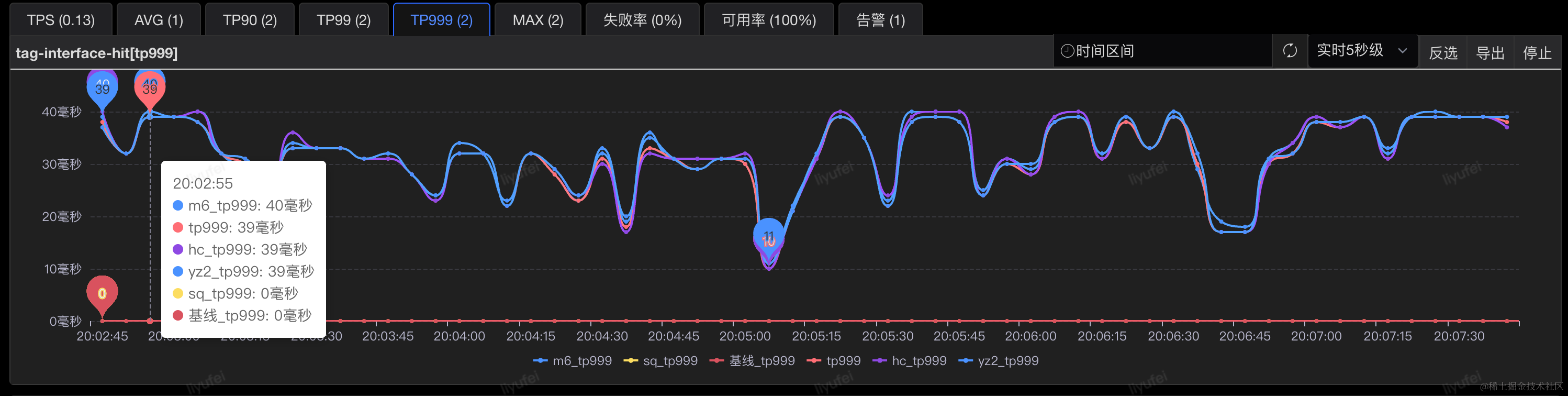
性能对比
接口整体TP999耗时从40ms下降到10ms以内

五、命中接口的后续探索
一、逆向存储
背景
我们对一些耗时长的请求进行分析时发现,有些业务方传的群体编码,一次可能传几十个,这种情况我们可能需要判定几十次,然后把结果返回给用户,性能肯定比一次只传一个群体会差。所以我们想使用用户的pin当作key,然后value是用户所在的群体数据。这样不管用户一次传多少个群体,我们只用取一次缓存就可以。
存储方式
key:用户的pin的offset为key
value:用户所在的所有群体集合(以位图的方式存储)
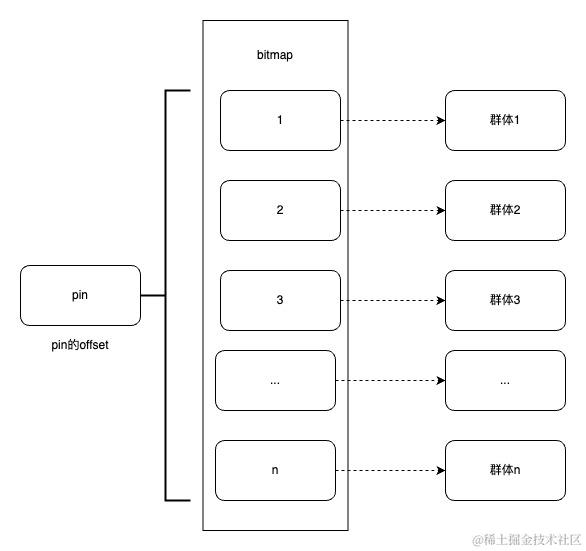
优势
•性能高:用户传多个群体编码的时候,我们只需要取一次缓存就可以,性能大大提高了。
二、规则判定
背景
发现有些用户在创建群体的时候,只用到了标签,然后对这些标签做逻辑与或非的操作。
举个例子:如果用户选择了两个标签(标签1:男性,标签2:三十岁以上,而且是且的关系)创建了一个人群,现在想判断一个pin是否在这个群体里面,我们可以怎么操作?我们只需要先判定用户是否是男性,然后判断用户是否三十岁以上,然后在内存中做逻辑且的操作就可以了。
优势
•存储空间:不用存储整个群体位图文件,而且标签位图可重复使用,大大节省了存储空间
六、相关技术附录
CDP系统中目前存在大量由pin集合组成的标签和群体,截止当前共有标签4000+,有效群体17000+。而且大量的群体都是pin数量都是千万级别以上,甚至有的群体pin数量达到了40亿+。如此大量的pin集合,对我们存储结构提出较高的要求。
这里拿群体举例,如果某群体包含1000W个pin,通过文本文件存储,大概需要150M,40亿的群体就达到了惊人的1504010=60000M,大约60G,而我们的群体数量已经达到了17000+,再加上标签数据,所需要的存储空间将不可接受。
并且,数据的存储只是其中一个方面,后续针对标签和群体的组合计算,创建出更细粒度的pin包也是一个挑战。
面对以上问题,CDP采用了Bitmap的思路来解决,不但解决了存储空间问题,而且Bitmap本身的交并差运算,能够很好的支持用户对不同标签和群体的组合计算,详细方案如下。
一、bitmap简介
它的基本思想是用bit位来唯一标记某个数值,这样可以用它来记录一个数值没有重复的数据元组。并且每一条数据只使用一个bit来标识,能够大大的节省存储空间。
比如,如果想存储一个数值数组[2,4,6,8]。
Java中如果用byte类型来存储,不考虑其他开销,需要4个字节的空间,一个字节8位,也就是4*8=32bit。
倘若使用更大的数据类型,存储空间也会相应增大,如使用Integer(4字节),则需要448=128bit。
而如果采用bitmap的思想,只需要构建一个8bit空间,也就是一个字节的空间来存储,如下图。
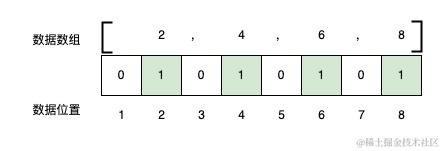
二、pin池编码
通过上文的例子,可以看到,使用Bitmap思想来存储,实际上每一个数据是一个bit,而且不能重复,这一点用户pin是符合的,没有重复的pin。
由于bitmap里只能存0或者1来标识当前位是否有值,而用户pin确是一个字符串,这就需要将数十亿的用户pin进行唯一性编码,这个编码也就是我们常说的offset偏移量。
每一个pin对应一个唯一的offset,目前已到46亿+,也就是说当前最大的偏移量是45亿+,这部分由数据同学帮我们加工一张pin池表,其中包含了pin和offset的对应关系。这样,新注册的pin,只要顺序增加offset值即可。
下边是一个简单示意图,假设我有8个pin,pin1pin8,对应的offset编号为18。
我要建一个只包含双数pin的标签或群体,则我只需要将offset为2,4,6,8的位设为1即可。
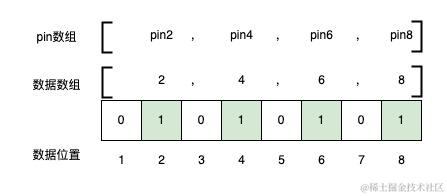
三、ClickHouse简介
有了位图之后,存在哪里,以及怎么进行位图之间的交并差的运算。基于这些问题,我们使用了ClickHouse(以下简称CK),一个由俄罗斯Yandex在2016年年开源的⾼性能分析型SQL数据库,是一个用于联机分析处理(OLAP)的列式数据库管理系统(columnar DBMS) 。
它具有以下特点:
1、完备的数据库管理功能,包括DML(数据操作语言)、DDL(数据定义语言)、权限控制、数据备份与恢复、分布式计算和管理。
2、列式存储与数据压缩: 数据按列存储,在按列聚合的场景下,可有效减少查询时所需扫描的数据量。同时,按列存储数据对数据压缩有天然的友好性(列数据的同类性),降低网络传输和磁盘 IO 的压力。
3、关系模型与SQL: ClickHouse使用关系模型描述数据并提供了传统数据库的概念(数据库、表、视图和函数等)。与此同时,使用标准SQL作为查询语言,使得它更容易理解和学习,并轻松与第三方系统集成。
4、数据分片与分布式查询: 将数据横向切分,分布到集群内各个服务器节点进行存储。与此同时,可将数据的查询计算下推至各个节点并行执行,提高查询速度。
更多特性可查看官方文档:https://clickhouse.com/docs/zh/introduction/distinctive-features
还可以查看同事的这篇文章:如何使用Clickhouse搭建数十亿级用户画像平台看这一篇就够了
除了上文CK的特性之外,它还具有分析数据高性能,开发流程简便,开源社区活跃度高,并且支持压缩位图等优势。
四、群体加工链路
基于上面对bitmap以及clickhouse的介绍,我们采用的是ClickHouse+Bitmap实现标签群体组合计算和群体的存储
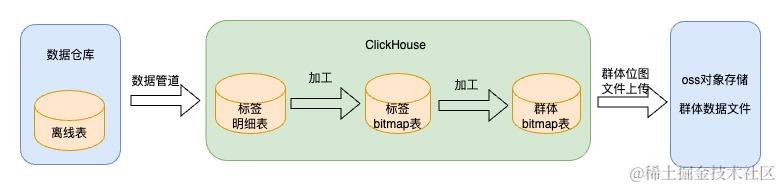
上图可以看到除了CK中的数据外,我们在OSS对象存储中也放了一份群体数据。
五、RoaringBitmap压缩
我们最终使用的是RoaringBitmap,一种高效的压缩位图实现,简称RBM。于2016年由S. Chambi、D. Lemire、O. Kaser等人在论文《Better bitmap performance with Roaring bitmaps》 《Consistently faster and smaller compressed bitmaps with Roaring》中提出。
基本实现思路如下:
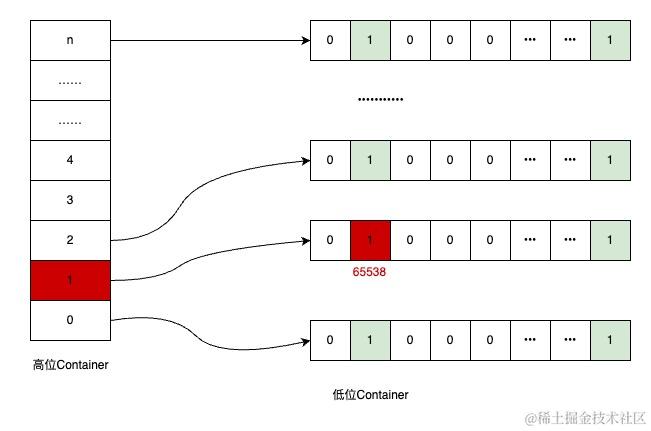
以整型int(32位)为例,将数据分成高16位和低16位两部分,低16位不变,作为数据位Container,高16位作为桶的编号Container,可以理解为高位的Container中,存放了很多个低位Container。
比如,我要存放65538这个值,则高位为65538>>>16=1,低位为65538-65536*1=2,即存储在1号桶的2号位置,存储位置如下图:
我们当前使用的RoaringBitmap版本为0.8.13,Container包含了三种实现:ArrayContainer(数组容器),
作者:京东科技 王京星
来源:京东云开发者社区
