







大家好,我是杯酒先生,这是我第一次写这种分享项目的文章,可能很水,很不全面,而且肯定存在说错的地方,希望大家可以评论里加以指点,不胜感激!
一、前言
网络爬虫(又称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。------百度百科
说人话就是,爬虫是用来海量规则化获取数据,然后进行处理和运用,在大数据、金融、机器学习等等方面都是必须的支撑条件之一。 目前在一线城市中,爬虫的岗位薪资待遇都是比较客观的,之后提升到中、高级爬虫工程师,数据分析师、大数据开发岗位等,都是很好的过渡。
二、项目目标
本此介绍的项目其实不用想的太过复杂,最终要实现的目标也就是将帖子的每条评论爬取到数据库中,并且做到可以更新数据,防止重复爬取,反爬等措施。
三、项目准备
这部分主要是介绍本文需要用到的工具,涉及的库,网页等信息等
软件:PyCharm
需要的库:Scrapy, selenium, pymongo, user_agent,datetime
目标网站:
http://bbs.foodmate.net
插件:chromedriver(版本要对)
四、项目分析
1、确定爬取网站的结构
简而言之:确定网站的加载方式,怎样才能正确的一级一级的进入到帖子中抓取数据,使用什么格式保存数据等。
其次,观察网站的层级结构,也就是说,怎么根据板块,一点点进入到帖子页面中,这对本次爬虫任务非常重要,也是主要编写代码的部分。
2、如何选择合适的方式爬取数据?
目前我知道的爬虫方法大概有如下(不全,但是比较常用):
1)request框架:运用这个http库可以很灵活的爬取需要的数据,简单但是过程稍微繁琐,并且可以配合抓包工具对数据进行获取。但是需要确定headers头以及相应的请求参数,否则无法获取数据;很多app爬取、图片视频爬取随爬随停,比较轻量灵活,并且高并发与分布式部署也非常灵活,对于功能可以更好实现。
2)scrapy框架:scrapy框架可以说是爬虫最常用,最好用的爬虫框架了,优点很多:scrapy 是异步的;采取可读性更强的 xpath 代替正则;强大的统计和 log 系统;同时在不同的 url 上爬行;支持 shell 方式,方便独立调试;支持写 middleware方便写一些统一的过滤器;可以通过管道的方式存入数据库等等。这也是本次文章所要介绍的框架(结合selenium库)。
五、项目实现
1、第一步:确定网站类型
首先解释一下是什么意思,看什么网站,首先要看网站的加载方式,是静态加载,还是动态加载(js加载),还是别的方式;根据不一样的加载方式需要不同的办法应对。然后我们观察今天爬取的网站,发现这是一个有年代感的论坛,首先猜测是静态加载的网站;我们开启组织 js 加载的插件,如下图所示。
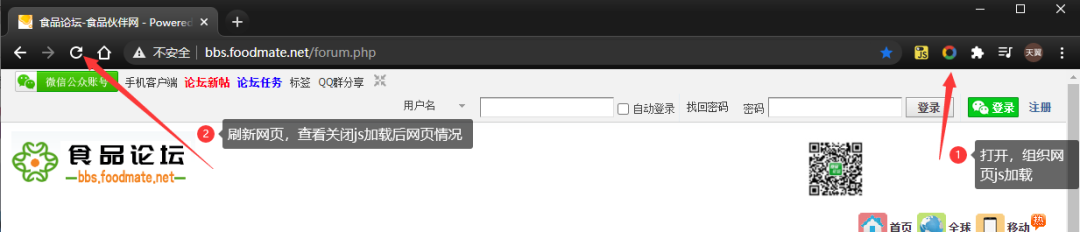
刷新之后发现确实是静态网站(如果可以正常加载基本都是静态加载的)。
2、第二步:确定层级关系
其次,我们今天要爬取的网站是食品论坛网站,是静态加载的网站,在之前分析的时候已经了解了,然后是层级结构:
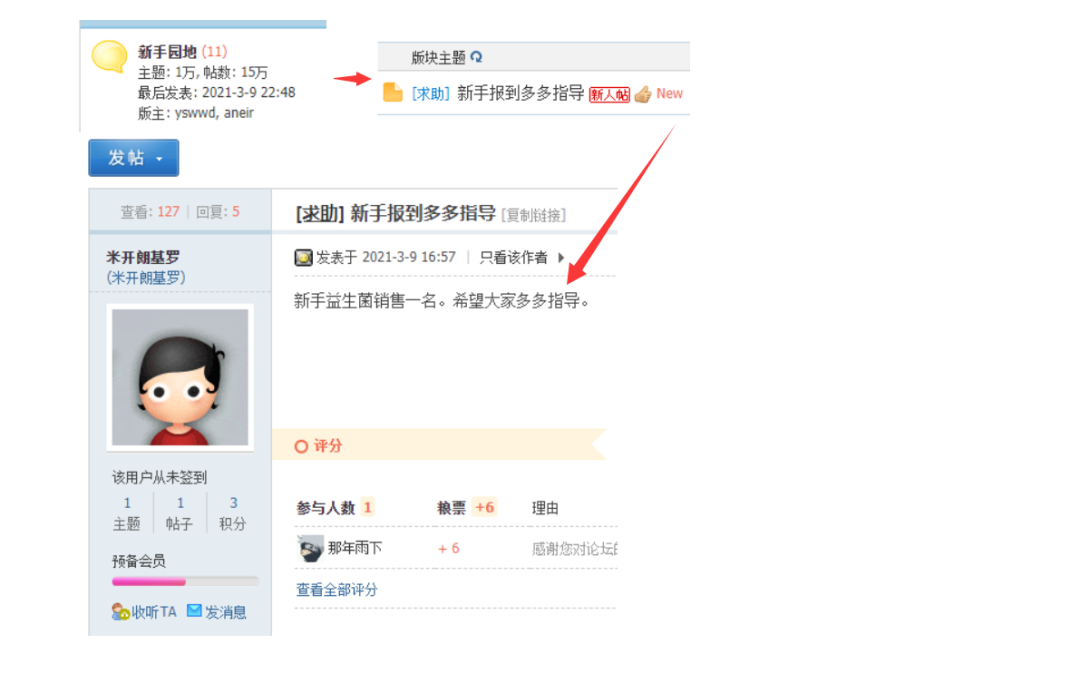
大概是上面的流程,总共有三级递进访问,之后到达帖子页面,如下图所示。

部分代码展示:
一级界面:
`def parse(self, response):` `self.logger.info("已进入网页!")` `self.logger.info("正在获取版块列表!")` `column_path_list = response.css('#ct > div.mn > div:nth-child(2) > div')[:-1]` `for column_path in column_path_list:` `col_paths = column_path.css('div > table > tbody > tr > td > div > a').xpath('@href').extract()` `for path in col_paths:` `block_url = response.urljoin(path)` `yield scrapy.Request(` `url=block_url,` `callback=self.get_next_path,` `)`
二级界面:
`def get_next_path(self, response):` `self.logger.info("已进入版块!")` `self.logger.info("正在获取文章列表!")` `if response.url == 'http://www.foodmate.net/know/':` `pass` `else:` `try:` `nums = response.css('#fd_page_bottom > div > label > span::text').extract_first().split(' ')[-2]` `except:` `nums = 1` `for num in range(1, int(nums) + 1):` `tbody_list = response.css('#threadlisttableid > tbody')` `for tbody in tbody_list:` `if 'normalthread' in str(tbody):` `item = LunTanItem()` `item['article_url'] = response.urljoin(` `tbody.css('* > tr > th > a.s.xst').xpath('@href').extract_first())` `item['type'] = response.css(` `'#ct > div > div.bm.bml.pbn > div.bm_h.cl > h1 > a::text').extract_first()` `item['title'] = tbody.css('* > tr > th > a.s.xst::text').extract_first()` `item['spider_type'] = "论坛"` `item['source'] = "食品论坛"` `if item['article_url'] != 'http://bbs.foodmate.net/':` `yield scrapy.Request(` `url=item['article_url'],` `callback=self.get_data,` `meta={'item': item, 'content_info': []}` `)` `try:` `callback_url = response.css('#fd_page_bottom > div > a.nxt').xpath('@href').extract_first()` `callback_url = response.urljoin(callback_url)` `yield scrapy.Request(` `url=callback_url,` `callback=self.get_next_path,` `)` `except IndexError:` `pass`
三级界面:
`def get_data(self, response):` `self.logger.info("正在爬取论坛数据!")` `item = response.meta['item']` `content_list = []` `divs = response.xpath('//*[@id="postlist"]/div')` `user_name = response.css('div > div.pi > div:nth-child(1) > a::text').extract()` `publish_time = response.css('div.authi > em::text').extract()` `floor = divs.css('* strong> a> em::text').extract()` `s_id = divs.xpath('@id').extract()` `for i in range(len(divs) - 1):` `content = ''` `try:` `strong = response.css('#postmessage_' + s_id[i].split('_')[-1] + '').xpath('string(.)').extract()` `for s in strong:` `content += s.split(';')[-1].lstrip('\r\n')` `datas = dict(content=content, # 内容` `reply_id=0, # 回复的楼层,默认0` `user_name=user_name[i], # ⽤户名` `publish_time=publish_time[i].split('于 ')[-1], # %Y-%m-%d %H:%M:%S'` `id='#' + floor[i], # 楼层` `)` `content_list.append(datas)` `except IndexError:` `pass` `item['content_info'] = response.meta['content_info']` `item['scrawl_time'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S')` `item['content_info'] += content_list` `data_url = response.css('#ct > div.pgbtn > a').xpath('@href').extract_first()` `if data_url != None:` `data_url = response.urljoin(data_url)` `yield scrapy.Request(` `url=data_url,` `callback=self.get_data,` `meta={'item': item, 'content_info': item['content_info']}` `)` `else:` `item['scrawl_time'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S')` `self.logger.info("正在存储!")` `print('储存成功')` `yield item`
3、第三步:确定爬取方法
由于是静态网页,首先决定采用的是scrapy框架直接获取数据,并且通过前期测试发现方法确实可行,不过当时年少轻狂,小看了网站的保护措施,由于耐心有限,没有加上定时器限制爬取速度,导致我被网站加了限制,并且网站由静态加载网页变为:动态加载网页验证算法之后再进入到该网页,直接访问会被后台拒绝。
但是这种问题怎么会难道我这小聪明,经过我短暂地思考(1天),我将方案改为scrapy框架 + selenium库的方法,通过调用chromedriver,模拟访问网站,等网站加载完了再爬取不就完了,后续证明这个方法确实可行,并且效率也不错。
实现部分代码如下:
`def process_request(self, request, spider):` `chrome_options = Options()` `chrome_options.add_argument('--headless') # 使用无头谷歌浏览器模式` `chrome_options.add_argument('--disable-gpu')` `chrome_options.add_argument('--no-sandbox')` `# 指定谷歌浏览器路径` `self.driver = webdriver.Chrome(chrome_options=chrome_options,` `executable_path='E:/pycharm/workspace/爬虫/scrapy/chromedriver')` `if request.url != 'http://bbs.foodmate.net/':` `self.driver.get(request.url)` `html = self.driver.page_source` `time.sleep(1)` `self.driver.quit()` `return scrapy.http.HtmlResponse(url=request.url, body=html.encode('utf-8'), encoding='utf-8',` `request=request)`
4、第四步:确定爬取数据的储存格式
这部分不用多说,根据自己需求,将需要爬取的数据格式设置在items.py中。在工程中引用该格式保存即可:
`class LunTanItem(scrapy.Item):` `"""` `论坛字段` `"""` `title = Field() # str: 字符类型 | 论坛标题` `content_info = Field() # str: list类型 | 类型list: [LunTanContentInfoItem1, LunTanContentInfoItem2]` `article_url = Field() # str: url | 文章链接` `scrawl_time = Field() # str: 时间格式 参照如下格式 2019-08-01 10:20:00 | 数据爬取时间` `source = Field() # str: 字符类型 | 论坛名称 eg: 未名BBS, 水木社区, 天涯论坛` `type = Field() # str: 字符类型 | 板块类型 eg: '财经', '体育', '社会'` `spider_type = Field() # str: forum | 只能写 'forum'`
5、第五步:确定保存数据库
本次项目选择保存的数据库为mongodb,由于是非关系型数据库,优点显而易见,对格式要求没有那么高,可以灵活储存多维数据,一般是爬虫优选数据库(不要和我说redis,会了我也用,主要是不会)
代码:
`import pymongo``class FMPipeline():` `def __init__(self):` `super(FMPipeline, self).__init__()` `# client = pymongo.MongoClient('139.217.92.75')` `client = pymongo.MongoClient('localhost')` `db = client.scrapy_FM` `self.collection = db.FM` `def process_item(self, item, spider):` `query = {` `'article_url': item['article_url']` `}` `self.collection.update_one(query, {"$set": dict(item)}, upsert=True)` `return item`
这时,有聪明的盆友就会问:如果运行两次爬取到了一样的数据怎么办呢?(换句话说就是查重功能)
这个问题之前我也没有考虑,后来在我询问大佬的过程中知道了,在我们存数据的时候就已经做完这件事了,就是这句:
`query = {` `'article_url': item['article_url']``}``self.collection.update_one(query, {"$set": dict(item)}, upsert=True)`
通过帖子的链接确定是否有数据爬取重复,如果重复可以理解为将其覆盖,这样也可以做到更新数据。
6、其他设置
像多线程、headers头,管道传输顺序等问题,都在settings.py文件中设置,具体可以参考小编的项目去看,这里不再赘述。
七、效果展示
1、点击运行,结果显示在控制台,如下图所示。

2、中间会一直向队列中堆很多帖子的爬取任务,然后多线程处理,我设置的是16线程,速度还是很可观的。
3、数据库数据展示:

content_info中存放着每个帖子的全部留言以及相关用户的公开信息。
八、总结
1、这篇文章主要给大家介绍了食品网站的数据采集和存储过程,详解了如何分析网页结构、爬虫策略、网站类型、层级关系、爬虫方法和数据存储过程,最终实现将帖子的每条评论爬取到数据库中,并且做到可以更新数据,防止重复爬取,反爬等,干货满满。
2、本次项目总的来说,不是特别难搞,只要思路对了,找到了数据规则,爬起来可以说易如反掌,觉得难只是之前没有完整走过流程,有了这次比较水的介绍,希望能对你有所帮助,那将是我最大的荣幸。
3、遇到问题首先想的不是问同事,朋友,老师,而是去谷歌,百度,看有没有相似的情况,看别人的经历,一定要学会自己发现问题,思考问题,解决问题,这对于之后工作有非常大的帮助(我之前就被说过还没有脱离学生时代,就是我喜欢问同事),等网上查询了一定资料了,还是没有头绪,再去问别人,别人也会比较愿意帮助你的~
我是杯酒先生,最后分享我的座右铭给大家:保持独立思考,不卑不亢不怂。
最后需要本文项目代码的小伙伴,请在公众号后台回复“食品论坛”关键字进行获取,如果在运行过程中有遇到任何问题,请随时留言或者加小编好友,小编看到会帮助大家解决bug噢!
想要学习更多网络爬虫知识,请点击阅读原文前往爬虫网站。
**-----**------**-----**---**** End **-----**--------**-----**-****

往期精彩文章推荐:

欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/YZ76EkZGMWO35nt4qtTNFQ,如有侵权,请联系删除。