







值就是函数,函数就是值。所有函数都消费函数,所有函数都生产函数。
"函数式编程", 又称泛函编程, 是一种"编程范式"(programming paradigm),也就是如何编写程序的方法论。它的基础是 λ 演算(lambda calculus)。λ演算可以接受函数当作输入(参数)和输出(返回值)。
和指令式编程相比,函数式编程的思维方式更加注重函数的计算。它的主要思想是把问题的解决方案写成一系列嵌套的函数调用。
就像在OOP中,一切皆是对象,编程的是由对象交合创造的世界;在FP中,一切皆是函数,编程的世界是由函数交合创造的世界。
函数式编程中最古老的例子莫过于1958年被创造出来的Lisp了。Lisp由约翰·麦卡锡(John McCarthy,1927-2011)在1958年基于λ演算所创造,采用抽象数据列表与递归作符号演算来衍生人工智能。较现代的例子包括Haskell、ML、Erlang等。现代的编程语言对函数式编程都做了不同程度的支持,例如:JavaScript, Coffee Script,PHP,Perl,Python, Ruby, C# , Java 等等(这将是一个不断增长的列表)。
函数式语言在Java 虚拟机(JVM)平台上也迅速地崭露头角,例如Scala 、Clojure ; .NET 平台也不例外,例如:F# 。
函数作为Kotlin中的一等公民,可以像其他对象一样作为函数的输入与输出。关于对函数式编程的支持,相对于Scala的学院派风格,Kotlin则是纯的的工程派:实用性、简洁性上都要比Scala要好。
本章我们来一起学习函数式编程以及在Kotlin中使用函数式编程的相关内容。
函数式编程概述

函数式编程思想是一个非常古老的思想。我们简述如下:
- 我们就从1900 年 David Hilbert 的第 10 问题(能否通过有限步骤来判定不定方程是否存在有理整数解?) 开始说起吧。
- 1920,Schönfinkel,组合子逻辑(combinatory logic)。直到 Curry Haskell 1927 在普林斯顿大学当讲师时重新发现了 Moses Schönfinkel 关于组合子逻辑的成果。Moses Schönfinkel的成果预言了很多 Curry 在做的研究,于是他就跑去哥廷根大学与熟悉Moses Schönfinkel工作的Heinrich Behmann、Paul Bernays两人一起工作,并于 1930 年以一篇组合子逻辑的论文拿到了博士学位。Curry Brooks Haskell 整个职业生涯都在研究组合子,实际开创了这个研究领域,λ演算中用单参数函数来表示多个参数函数的方法被称为 Currying (柯里化),虽然 Curry 同学多次指出这个其实是 Schönfinkel 已经搞出来的,不过其他人都是因为他用了才知道,所以这名字就这定下来了;并且有三门编程语言以他的名字命名,分别是:Curry, Brooks, Haskell。Curry 在 1928 开始开发类型系统,他搞的是基于组合子的 polymorphic,Church 则建立了基于函数的简单类型系统。
- 1929, 哥德尔(Kurt Gödel )完备性定理。Gödel 首先证明了一个形式系统中的所有公式都可以表示为自然数,并可以从一自然数反过来得出相应的公式。这对于今天的程序员都来说,数字编码、程序即数据计算机原理最核心、最基本的常识,在那个时代却脑洞大开的创见。
- 1933,λ 演算。 Church 在 1933 年搞出来一套以纯λ演算为基础的逻辑,以期对数学进行形式化描述。 λ 演算和递归函数理论就是函数式编程的基础。
- 1936,确定性问题(decision problem,德文 Entscheidungsproblem (发音 [ɛntˈʃaɪ̯dʊŋspʁoˌbleːm])。 Alan Turing 和 Alonzo Church,两人在同在1936年独立给出了否定答案。
1935-1936这个时间段上,我们有了三个有效计算模型:通用图灵机、通用递归函数、λ可定义。Rosser 1939 年正式确认这三个模型是等效的。
- 1953-1957,FORTRAN (FORmula TRANslating ),John Backus。1952 年 Halcombe Laning 提出了直接输入数学公式的设想,并制作了 GEORGE编译器演示该想法。受这个想法启发,1953 年 IBM 的 John Backus 团队给 IBM 704 主机研发数学公式翻译系统。第一个 FORTRAN (FORmula TRANslating 的缩写)编译器 1957.4 正式发行。FORTRAN 程序的代码行数比汇编少20倍。FORTRAN 的成功,让很多人认识到直接把代数公式输入进电脑是可行的,并开始渴望能用某种形式语言直接把自己的研究内容输入到电脑里进行运算。John Backus 在1970年代搞了 FP 语言,1977 年发表。虽然这门语言并不是最早的函数式编程语言,但他是 Functional Programming 这个词儿的创造者, 1977 年他的图灵奖演讲题为[“Can Programming Be Liberated From the von Neumann Style? A Functional Style and its Algebra of Programs”]
- 1956, LISP, John McCarthy。John McCarthy 1956年在 Dartmouth一台 IBM 704 上搞人工智能研究时,就想到要一个代数列表处理(algebraic list processing)语言。他的项目需要用某种形式语言来编写语句,以记录关于世界的信息,而他感觉列表结构这种形式挺合适,既方便编写,也方便推演。于是就创造了LISP。正因为是在 IBM 704 上开搞的,所以 LISP 的表处理函数才会有奇葩的名字: car/cdr 什么的。其实是取 IBM704 机器字的不同部分,c=content of,r=register number, a=address part, d=decrement part 。
面向对象编程(OOP)与面向函数编程(FOP)
面向对象编程(OOP)
在OOP中,一切皆是对象。
在面向对象的命令式(imperative)编程语言里面,构建整个世界的基础是类和类之间沟通用的消息,这些都可以用类图(class diagram)来表述。《设计模式:可复用面向对象软件的基础》(Design Patterns: Elements of Reusable Object-Oriented Software,作者ErichGamma、Richard Helm、Ralph Johnson、John Vlissides)一书中,在每一个模式的说明里都附上了至少一幅类图。
OOP 的世界提倡开发者针对具体问题建立专门的数据结构,相关的专门操作行为以“方法”的形式附加在数据结构上,自顶向下地来构建其编程世界。
OOP追求的是万事万物皆对象的理念,自然地弱化了函数。例如:函数无法作为普通数据那样来传递(OOP在函数指针上的约束),所以在OOP中有各种各样的、五花八门的设计模式。
GoF所著的《设计模式-可复用面向对象软件的基础》从面向对象设计的角度出发的,通过对封装、继承、多态、组合等技术的反复使用,提炼出一些可重复使用的面向对象设计技巧。而多态在其中又是重中之重。
多态、面向接口编程、依赖反转等术语,描述的思想其实是相同的。这种反转模式实现了模块与模块之间的解耦。这样的架构是健壮的, 而为了实现这样的健壮系统,在系统架构中基本都需要使用多态性。
绝大部分设计模式的实现都离不开多态性的思想。换一种说法就是,这些设计模式背后的本质其实就是OOP的多态性,而OOP中的多态本质上又是受约束的函数指针。
引用Charlie Calverts对多态的描述: “多态性是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。”
简单的说,就是一句话:允许将子类类型的指针赋值给父类类型的指针。而我们在OOP中的那么多的设计模式,其实就是在OOP的多态性的约束规则下,对这些函数指针的调用模式的总结。
很多设计模式,在函数式编程中都可以用高阶函数来代替实现:
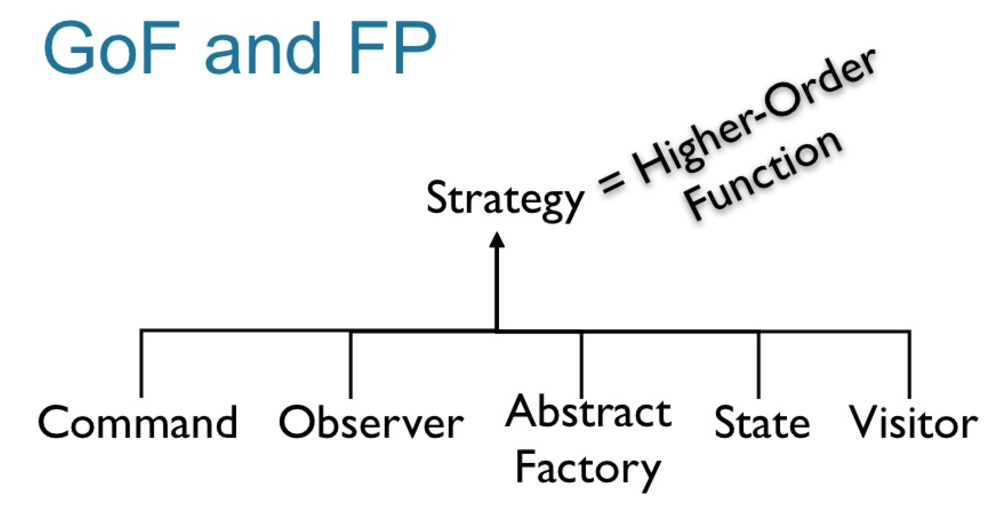
面向函数编程(FOP)
在FP中,一切皆是函数。
函数式编程(FP)是关于不变性和函数组合的一种编程范式。
函数式编程语言实现重用的思路很不一样。函数式语言提倡在有限的几种关键数据结构(如list、set、map)上 , 运用函数的组合 ( 高阶函数) 操作,自底向上地来构建世界。
当然,我们在工程实践中,是不能极端地追求纯函数式的编程的。一个简单的原因就是:性能和效率。例如:对于有状态的操作,命令式操作通常会比声明式操作更有效率。纯函数式编程是解决某些问题的伟大工具,但是在另外的一些问题场景中,并不适用。因为副作用总是真实存在。
OOP喜欢自顶向下架构层层分解(解构),FP喜欢自底向上层层组合(复合)。 而实际上,编程的本质就是次化分解与复合的过程。通过这样的过程,创造一个美妙的逻辑之塔世界。
我们经常说一些代码片段是优雅的或美观的,实际上意味着它们更容易被人类有限的思维所处理。
对于程序的复合而言,好的代码是它的表面积要比体积增长的慢。
代码块的“表面积”是是我们复合代码块时所需要的信息(接口API协议定义)。代码块的“体积”就是接口内部的实现逻辑(API内部的实现代码)。
在OOP中,一个理想的对象应该是只暴露它的抽象接口(纯表面, 无体积),其方法则扮演箭头的角色。如果为了理解一个对象如何与其他对象进行复合,当你发现不得不深入挖掘对象的实现之时,此时你所用的编程范式的原本优势就荡然无存了。
FP通过函数组合来构造其逻辑系统。FP倾向于把软件分解为其需要执行的行为或操作,而且通常采用自底向上的方法。函数式编程也提供了非常强大的对事物进行抽象和组合的能力。
在FP里面,函数是“一类公民”(first-class)。它们可以像1, 2, "hello",true,对象…… 之类的“值”一样,在任意位置诞生,通过变量,参数和数据结构传递到其它地方,可以在任何位置被调用。
而在OOP中,很多所谓面向对象设计模式(design pattern),都是因为面向对象语言没有first-class function(对应的是多态性),所以导致了每个函数必须被包在一个对象里面(受约束的函数指针)才能传递到其它地方。
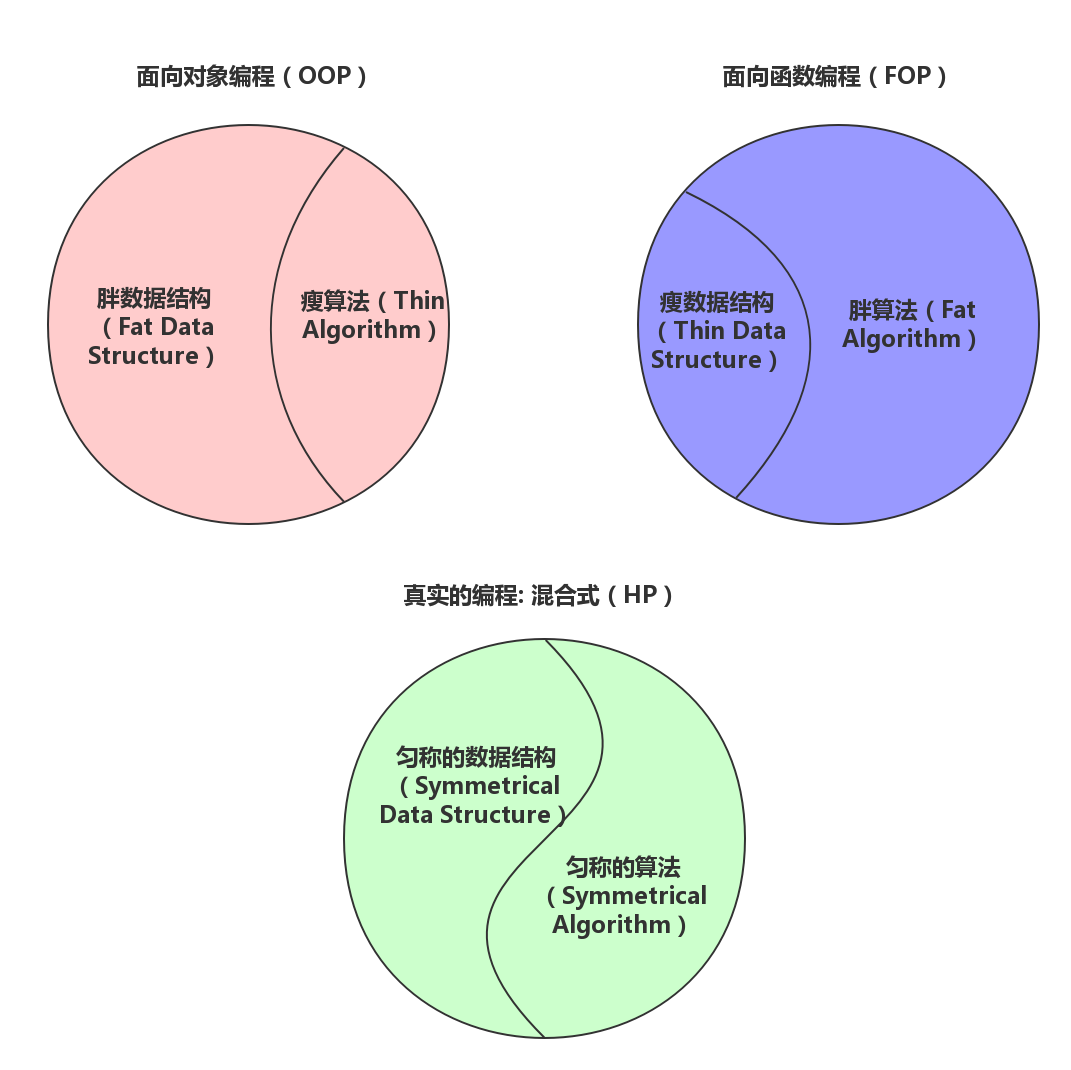
匀称的数据结构 + 匀称的算法
在面向对象式的编程中,一切皆是对象(偏重数据结构、数据抽象,轻算法)。我们把它叫做:胖数据结构-瘦算法(FDS-TA)。
在面向函数式的编程中,一切皆是函数(偏重算法,轻数据结构)。我们把它叫做:瘦数据结构-胖算法(TDS-FA)。
可是,这个世界很复杂,你怎么能说一切皆是啥呢?真实的编程世界,自然是匀称的数据结构结合匀称的算法(SDS-SA)来创造的。
我们在编程中,不可能使用纯的对象(对象的行为方法其实就是函数),或者纯的函数(调用函数的对象、函数操作的数据其实就是数据结构)来创造一个完整的世界。如果数据结构是阴,算法是阳,那么在解决实际问题中,往往是阴阳交合而成世界。还是那句经典的:
程序 = 匀称的数据结构 + 匀称的算法
我们用一幅图来简单说明:
函数与映射
一切皆是映射。函数式编程的代码主要就是“对映射的描述”。我们说组合是编程的本质,其实,组合就是建立映射关系。
一个函数无非就是从输入到输出的映射,写成数学表达式就是:
f: X -> Y p:Y -> Z p(f) : X ->Z
用编程语言表达就是:
fun f(x:X) : Y{} fun p(y:Y) : Z{} fun fp(f: (X)->Y, p: (Y)->Z) : Z { return {x -> p(f(x))} }
函数式编程基本特性
在经常被引用的论文 “Why Functional Programming Matters” 中,作者 John Hughes 说明了模块化是成功编程的关键,而函数编程可以极大地改进模块化。
在函数编程中,我们有一个内置的框架来开发更小的、更简单的和更一般化的模块, 然后将它们组合在一起。
函数编程的一些基本特点包括:
- 函数是"第一等公民"。
- 闭包(Closure)和高阶函数(Higher Order Function)。
- Lambda演算与函数柯里化(Currying)。
- 懒惰计算(lazy evaluation)。
- 使用递归作为控制流程的机制。
- 引用透明性。
- 没有副作用。
组合与范畴
函数式编程的本质是函数的组合,组合的本质是范畴(Category)。
和搞编程的一样,数学家喜欢将问题不断加以抽象从而将本质问题抽取出来加以论证解决,范畴论就是这样一门以抽象的方法来处理数学概念的学科,主要用于研究一些数学结构之间的映射关系(函数)。
在范畴论里,一个范畴(category)由三部分组成:
- 对象(object).
- 态射(morphism).
- 组合(composition)操作符,
范畴的对象
这里的对象可以看成是一类东西,例如数学上的群,环,以及有理数,无理数等都可以归为一个对象。对应到编程语言里,可以理解为一个类型,比如说整型,布尔型等。
态射
态射指的是一种映射关系,简单理解,态射的作用就是把一个对象 A 里的值 a 映射为 另一个对象 B 里的值 b = f(a),这就是映射的概念。
态射的存在反映了对象内部的结构,这是范畴论用来研究对象的主要手法:对象内部的结构特性是通过与别的对象的映射关系反映出来的,动静是相对的,范畴论通过研究映射关系来达到探知对象的内部结构的目的。
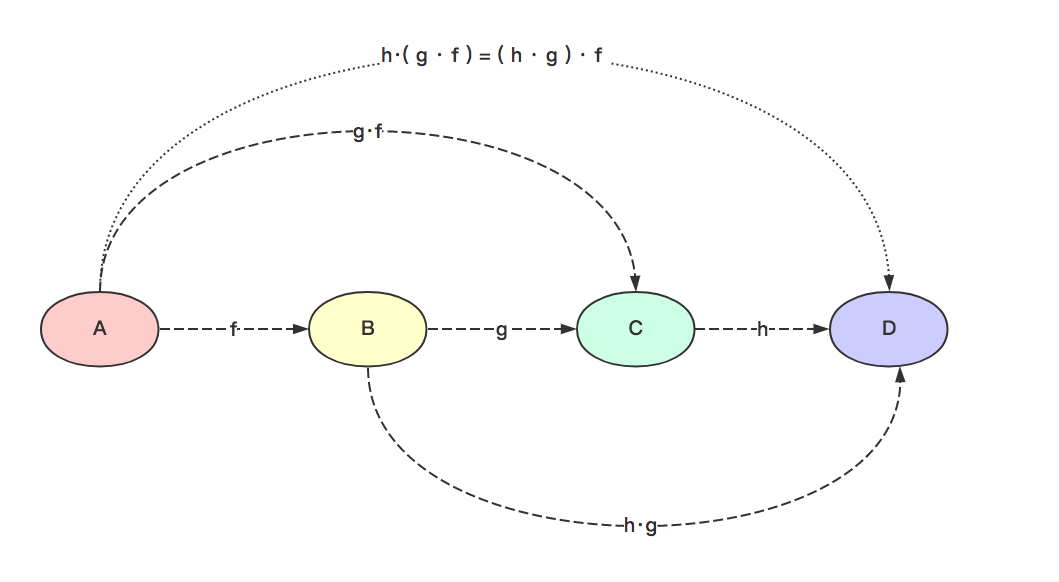
组合操作符
组合操作符,用点(.)表示,用于将态射进行组合。组合操作符的作用是将两个态射进行组合,例如,假设存在态射 f: A -> B, g: B -> C, 则 g.f : A -> C.
一个结构要想成为一个范畴, 除了必须包含上述三样东西,它还要满足以下三个限制:
- 结合律: f.(g.h) = (f.g).h 。
- 封闭律:如果存在态射 f, g,则必然存在 h = f.g 。
- 同一律:对结构中的每一个对象 A, 必须存在一个单位态射 Ia: A -> A, 对于单位态射,显然,对任意其它态射 f, 有 f.I = f。
在范畴论里另外研究的重点是范畴与范畴之间的关系,就正如对象与对象之间有态射一样,范畴与范畴之间也存在映射关系,从而可以将一个范畴映射为另一个范畴,这种映射在范畴论中叫作函子(functor),具体来说,对于给定的两个范畴 A 和 B, 函子的作用有两个:
- 将范畴 A 中的对象映射到范畴 B 中的对象。
- 将范畴 A 中的态射映射到范畴 B 中的态射。
显然,函子反映了不同的范畴之间的内在联系。跟函数和泛函数的思想是相同的。
而我们的函数式编程探究的问题与思想理念可以说是跟范畴论完全吻合。如果把函数式编程的整个的世界看做一个对象,那么FP真正搞的事情就是建立通过函数之间的映射关系,来构建这样一个美丽的编程世界。
很多问题的解决(证明)其实都不涉及具体的(数据)结构,而完全可以只依赖映射之间的组合运算(composition)来搞定。这就是函数式编程的核心思想。
如果我们把程序看做图论里面的一张图G,数据结构当作是图G的节点Node(数据结构,存储状态), 而算法逻辑就是这些节点Node之间的Edge (数据映射,Mapping), 那么这整幅图 G(N,E) 就是一幅美妙的抽象逻辑之塔的 映射图 , 也就是我们编程创造的世界:

函数是"第一等公民"
函数式编程(FP)中,函数是"第一等公民"。
所谓"第一等公民"(first class),有时称为 闭包 或者 仿函数(functor)对象,指的是函数与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值。这个以函数为参数的概念,跟C语言中的函数指针类似。
举例来说,下面代码中的print变量就是一个函数(没有函数名),可以作为另一个函数的参数:
>>> val print = fun(x:Any){println(x)} >>> listOf(1,2,3).forEach(print) 1 2 3
高阶函数(Higher order Function)
FP 语言支持高阶函数,高阶函数就是多阶映射。高阶函数用另一个函数作为其输入参数,也可以返回一个函数作为输出。
代码示例:
fun isOdd(x: Int) = x % 2 != 0 fun length(s: String) = s.length fun <A, B, C> compose(f: (B) -> C, g: (A) -> B): (A) -> C { return { x -> f(g(x)) } }
测试代码:
fun main(args: Array<String>) { val oddLength = compose(::isOdd, ::length) val strings = listOf("a", "ab", "abc") println(strings.filter(oddLength)) // [a, abc] }
这个compose函数,其实就是数学中的复合函数的概念,这是一个高阶函数的例子:传入的两个参数f , g都是函数,其返回值也是函数。
图示如下:

这里的
fun <A, B, C> compose(f: (B) -> C, g: (A) -> B): (A) -> C
中类型参数对应:
fun <String, Int, Boolean> compose(f: (Int) -> Boolean, g: (String) -> Int): (String) -> Boolean
这里的(Int) -> Boolean 、(String) -> Int、 (String) -> Boolean 都是函数类型。
其实,从映射的角度看,就是二阶映射。对[a, ab, abc] 中每个元素 x 先映射成长度g(x) = 1, 2, 3 , 再进行第二次映射:f(g(x)) %2 != 0 , 长度是奇数?返回值是true的被过滤出来。
有了高阶函数,我们可以用优雅的方式进行模块化编程。
另外,高阶函数满足结合律:
λ演算 (Lambda calculus 或者 λ-calculus)
𝜆 演算是函数式语言的基础。在λ-演算的基础上,发展起来的π-演算、χ-演算,成为近年来的并发程序的理论工具之一,许多经典的并发程序模型就是以π-演算为框架的。λ 演算神奇之处在于,通过最基本的函数抽象和函数应用法则,配套以适当的技巧,便能够构造出任意复杂的可计算函数。
λ演算是一套用于研究函数定义、函数应用和递归的形式系统。它由 阿隆佐·丘奇(Alonzo Church,1903~1995)和 Stephen Cole Kleene 在 20 世纪三十年代引入。当时的背景是解决函数可计算的本质性问题,初期λ演算成功的解决了在可计算理论中的判定性问题,后来根据Church–Turing thesis,证明了λ演算与图灵机是等价的。
λ 演算可以被称为最小的通用程序设计语言。它包括一条变换规则 (变量替换) 和一条函数定义方式,λ演算之通用在于,任何一个可计算函数都能用这种形式来表达和求值。
λ演算强调的是变换规则的运用,这里的变换规则本质上就是函数映射。 Lambda 表达式(Lambda Expression) 是 λ演算 的一部分。
λ演算中一切皆函数,全体λ表达式构成Λ空间,λ表达式为Λ空间到Λ空间的函数。
例如,在 lambda 演算中有许多方式都可以定义自然数,最常见的是Church 整数,定义如下:
0 = λ f. λ x. x 1 = λ f. λ x. f x 2 = λ f. λ x. f (f x) 3 = λ f. λ x. f (f (f x)) ...
数学家们都崇尚简洁,只用一个关键字 'λ' 来表示对函数的抽象。
其中的λ f. λ x.,λ f 是抽象出来的函数, λ x是输入参数, . 语法用来分割参数表和函数体。 为了更简洁,我们简记为F, 那么上面的Church 整数定义简写为:
0 = F x 1 = F f x 2 = F f (f x) 3 = F f (f (f x)) ...
使用λ演算定义布尔值:
TRUE = λ x. λ y. x FALSE = λ x. λ y. y
用图示如下:


在λ演算中只有函数,一门编程语言中的数据类型,比如boolean、number、list等,都可以使用纯λ演算来实现。我们不用去关心数据的值是什么,重点是我们能对这个值做什么操作(apply function)。
使用λ演算定义一个恒等函数I :
I = λ x . x
使用Kotlin代码来写,如下:
>>> val I = {x:Int -> x} >>> I(0) 0 >>> I(1) 1 >>> I(100) 100
对 I 而言任何一个 x 都是它的不动点(即对某个函数 f(x) 存在这样的一个输入 x,使得函数的输出仍旧等于输入的 x 。形式化的表示即为 f(x) = x )。
再例如,下面的 λ 表达式表示将x映射为 x+1 :
λ x . x + 1
测试代码:
( λ x . x + 1) 5
将输出6 。
这样的表达式,在Kotlin中, 如果使用Lambda表达式我们这样写:
>>> val addOneLambda = { ... x: Int -> ... x + 1 ... } >>> addOneLambda(1) 2
如果使用匿名函数,这样写:
>>> val addOneAnonymouse = (fun(x: Int): Int { ... return x + 1 ... }) >>> addOneAnonymouse(1) 2
在一些古老的编程语言中,lambda表达式还是比较接近lambda演算的表达式的。在现代程序语言中的lambda表达式,只是取名自lambda演算,已经与原始的lambda演算有很大差别了。例如:

在Javascript里没有任何语法专门代表lambda, 只写成这样的嵌套函数function{ return function{...} }。
函数柯里化(Currying)
很多基于 lambda calculus 的程序语言,比如 ML 和 Haskell,都习惯用currying 的手法来表示函数。比如,如果你在 Haskell 里面这样写一个函数:
f x y = x + y
然后你就可以这样把链表里的每个元素加上 2:
map (f 2) [1, 2, 3]
它会输出 [3, 4, 5]。
Currying 用一元函数,来组合成多元函数。比如,上面的函数 f 的定义在 Scheme 里面相当于:
(define f (lambda (x) (lambda (y) (+ x y))))
它是说,函数 f,接受一个参数 x,返回另一个函数(没有名字)。这个匿名函数,如果再接受一个参数 y,就会返回 x + y。所以上面的例子里面,(f 2) 返回的是一个匿名函数,它会把 2 加到自己的参数上面返回。所以把它 map 到 [1, 2, 3],我们就得到了 [3, 4, 5]。
我们再使用Kotlin中的函数式编程来举例说明。
首先,我们看下普通的二元函数的写法:
fun add(x: Int, y: Int): Int { return x + y } add(1, 2) // 输出3
这种写法最简单,只有一层映射。
柯里化的写法:
fun curryAdd(x: Int): (Int) -> Int { return { y -> x + y } } curryAdd(1)(2)// 输出3
我们先传入参数x = 1, 返回函数 curryAdd(1) = 1 + y; 然后传入参数 y = 2, 返回最终的值 curryAdd(1)(2) = 3。
当然,我们也有 λ 表达式的写法:
val lambdaCurryAdd = { x: Int -> { y: Int -> x + y } } lambdaCurryAdd(1)(2) // 输出 3
这个做法其实来源于最早的 lambda calculus 的设计。因为 lambda calculus 的函数都只有一个参数,所以为了能够表示多参数的函数, Haskell Curry (数学家和逻辑学家),发明了这个方法。
不过在编码实践中,Currying 的工程实用性、简洁性上不是那么的友好。大量使用 Currying,会导致代码可读性降低,复杂性增加,并且还可能因此引起意想不到的错误。 所以在我们的讲求工程实践性能的Kotlin语言中,
古老而美丽的理论,也许能够给我带来思想的启迪,但是在工程实践中未必那么理想。
闭包(Closure)
闭包简单讲就是一个代码块,用{ }包起来。此时,程序代码也就成了数据,可以被一个变量所引用(与C语言的函数指针比较类似)。闭包的最典型的应用是实现回调函数(callback)。
闭包包含以下两个组成部分:
- 要执行的代码块(由于自由变量被包含在代码块中,这些自由变量以及它们引用的对象没有被释放)
- 自由变量的作用域
在PHP、Scala、Scheme、Common Lisp、Smalltalk、Groovy、JavaScript、Ruby、 Python、Go、Lua、objective c、swift 以及Java(Java8及以上)等语言中都能找到对闭包不同程度的支持。
Lambda表达式可以表示闭包。
惰性计算
除了高阶函数、闭包、Lambda表达式的概念,FP 还引入了惰性计算的概念。惰性计算(尽可能延迟表达式求值)是许多函数式编程语言的特性。惰性集合在需要时提供其元素,无需预先计算它们,这带来了一些好处。首先,您可以将耗时的计算推迟到绝对需要的时候。其次,您可以创造无限个集合,只要它们继续收到请求,就会继续提供元素。第三,map 和 filter 等函数的惰性使用让您能够得到更高效的代码(请参阅 参考资料 中的链接,加入由 Brian Goetz 组织的相关讨论)。
在惰性计算中,表达式不是在绑定到变量时立即计算,而是在求值程序需要产生表达式的值时进行计算。
一个惰性计算的例子是生成无穷 Fibonacci 列表的函数,但是对 第 n 个Fibonacci 数的计算相当于只是从可能的无穷列表中提取一项。
递归函数
递归指的是一个函数在其定义中直接或间接调用自身的一种方法, 它通常把一个大型的复杂的问题转化为一个与原问题相似的规模较小的问题来解决(复用函数自身), 这样可以极大的减少代码量。递归分为两个阶段:
1.递推:把复杂的问题的求解推到比原问题简单一些的问题的求解; 2.回归:当获得最简单的情况后,逐步返回,依次得到复杂的解。
递归的能力在于用有限的语句来定义对象的无限集合。
使用递归要注意的有两点:
(1)递归就是在过程或函数里面调用自身;
(2)在使用递归时,必须有一个明确的递归结束条件,称为递归出口。
下面我们举例说明。
阶乘函数 fact(n) 一般这样递归地定义:
fact(n) = if n=0 then 1 else n * fact(n-1)
我们使用Kotlin代码实现这个函数如下:
fun factorial(n: Int): Int { println("factorial() called! n=$n") if (n == 0) return 1; return n * factorial(n - 1); }
测试代码:
@Test fun testFactorial() { Assert.assertTrue(factorial(0) == 1) Assert.assertTrue(factorial(1) == 1) Assert.assertTrue(factorial(3) == 6) Assert.assertTrue(factorial(10) == 3628800) }
输出:
factorial() called! n=0 factorial() called! n=1 factorial() called! n=0 factorial() called! n=3 factorial() called! n=2 factorial() called! n=1 factorial() called! n=0 factorial() called! n=10 factorial() called! n=9 factorial() called! n=8 factorial() called! n=7 factorial() called! n=6 factorial() called! n=5 factorial() called! n=4 factorial() called! n=3 factorial() called! n=2 factorial() called! n=1 factorial() called! n=0 BUILD SUCCESSFUL in 24s 6 actionable tasks: 5 executed, 1 up-to-date
我们可以看到在factorial计算的过程中,函数不断的调用自身,然后不断的展开,直到最后到达了终止的n==0,这是递归的原则之一,就是在递归的过程中,传递的参数一定要不断的接近终止条件,在上面的例子中就是n的值不断减少,直至最后为0。
再举个Fibonacci数列的例子。
Fibonacci数列用数学中的数列的递归表达式定义如下:
fibonacci (0) = 0 fibonacci (1) = 1 fibonacci (n) = fibonacci (n - 1) + fibonacci (n - 2)
我们使用Kotlin代码实现它:
fun fibonacci(n: Int): Int { if (n == 1 || n == 2) return 1; return fibonacci(n - 1) + fibonacci(n - 2); }
测试代码:
@Test fun testFibonacci() { Assert.assertTrue(fibonacci(1) == 1) Assert.assertTrue(fibonacci(2) == 1) Assert.assertTrue(fibonacci(3) == 2) Assert.assertTrue(fibonacci(4) == 3) Assert.assertTrue(fibonacci(5) == 5) Assert.assertTrue(fibonacci(6) == 8) }
外篇: Scheme中的递归写法
因为Scheme 程序中充满了一对对嵌套的小括号,这些嵌套的符号体现了最基本的数学思想——递归。所以,为了多维度的来理解递归,我们给出Scheme中的递归写法:
(define factorial (lambda (n) (if (= n 0) 1 (* n (factorial (- n 1)))))) (define fibonacci (lambda (n) (cond ((= n 0) 0) ((= n 1) 1) (else (+ (fibonacci (- n 1)) (fibonacci (- n 2)))))))
其中关键字lambda, 表明我们定义的(即任何封闭的开括号立即离开λ及其相应的关闭括号)是一个函数。
Lambda演算和函数式语言的计算模型天生较为接近,Lambda表达式一般是这些语言必备的基本特性。
Scheme是Lisp方言,遵循极简主义哲学,有着独特的魅力。Scheme的一个主要特性是可以像操作数据一样操作函数调用。
Y组合子(Y - Combinator)
在现代编程语言中,函数都是具名的,而在传统的Lambda Calculus中,函数都是没有名字的。这样就出现了一个问题 —— 如何在Lambda Calculus中实现递归函数,即匿名递归函数。Haskell B. Curry (编程语言 Haskell 就是以此人命名的)发现了一种不动点组合子 —— Y Combinator,用于解决匿名递归函数实现的问题。Y 组合子(Y Combinator),其定义是:
Y = λf.(λx.f (x x)) (λx.f (x x))
对于任意函数 g,可以通过推导得到Y g = g (Y g)((高阶)函数的不动点 ),从而证明 λ演算 是 图灵完备 的。 Y 组合子 的重要性由此可见一斑。
她让人绞尽脑汁,也琢磨不定!她让人心力憔悴,又百般回味! 她,看似平淡,却深藏玄机!她,貌不惊人,却天下无敌! 她是谁?她就是 Y 组合子:Y = λf.(λx.f (x x)) (λx.f (x x)),不动点组合子中最著名的一个。
Y 组合子让我们可以定义匿名的递归函数。Y组合子是Lambda演算的一部分,也是函数式编程的理论基础。仅仅通过Lambda表达式这个最基本的 原子 实现循环迭代。Y 组合子本身是函数,其输入也是函数(在 Lisp 中连程序都是函数)。
颇有道生一、一生二、二生三、三生万物的韵味。
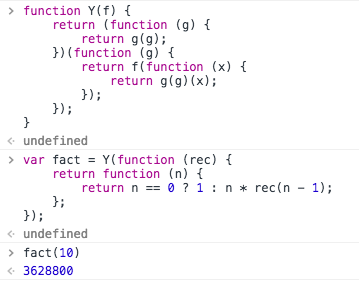
举个例子说明: 我们先使用类C语言中较为熟悉的JavaScript来实现一个Y组合子函数, 因为JavaScript语言的动态特性,使得该实现相比许多需要声明各种类型的语言要简洁许多:
function Y(f) { return (function (g) { return g(g); })(function (g) { return f(function (x) { return g(g)(x); }); }); } var fact = Y(function (rec) { return function (n) { return n == 0 ? 1 : n * rec(n - 1); }; });
我们使用了Y函数组合一段匿名函数代码,实现了一个匿名的递归阶乘函数。
直接将这两个函数放到浏览器的Console中去执行,我们将看到如下输出:
fact(10) 3628800
这个Y函数相当绕脑。要是在Clojure(JVM上的Lisp方言)中,这个Y函数实现如下:
(defn Y [r] ((fn [f] (f f)) (fn [f] (r (fn [x] ((f f) x))))))
使用Scheme语言来表达:
(define Y (lambda (f) ((lambda (x) (f (lambda (y) ((x x) y)))) (lambda (x) (f (lambda (y) ((x x) y)))))))
我们可以看出,使用Scheme语言表达的Y组合子跟 原生的 λ演算 表达式基本一样。
用CoffeeScript实现一个 Y combinator就长这样:
coffee> Y = (f) -> ((x) -> (x x)) ((x) -> (f ((y) -> ((x x) y)))) [Function]
这个看起就相当简洁优雅了。我们使用这个 Y combinator 实现一个匿名递归的Fibonacci函数:
coffee> fib = Y (f) -> (n) -> if n < 2 then n else f(n-1) + f(n-2) [Function] coffee> index = [0..10] [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ] coffee> index.map(fib) [ 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55 ]
实现一个匿名递归阶乘函数:
coffee> fact = Y (f) ->(n) -> if n==0 then 1 else n*f(n-1) [Function] coffee> fact(10) 3628800
上面的Coffee代码的命令行REPL运行环境搭建非常简单:
$ npm install -g coffee-script $ coffee coffee>
对CoffeeScript感兴趣的读者,可以参考:http://coffee-script.org/。
但是,这个Y组合子 要是 使用 OOP 语言编程范式, 就要显得复杂许多。为了更加深刻地认识OOP 与 FP编程范式,我们使用Java 8 以及 Kotlin 的实例来说明。这里使用Java给出示例的原因,是为了给出Kotlin与Java语言上的对比,在下一章节中,我们将要学习Kotlin与Java的互操作。
首先我们使用Java的匿名内部类实现Y组合子 :
package com.easy.kotlin; /** * Created by jack on 2017/7/9. */ public class YCombinator { public static Lambda<Lambda> yCombinator(final Lambda<Lambda> f) { return new Lambda<Lambda>() { @Override public Lambda call(Object input) { final Lambda<Lambda> u = (Lambda<Lambda>)input; return u.call(u); } }.call(new Lambda<Lambda>() { @Override public Lambda call(Object input) { final Lambda<Lambda> x = (Lambda<Lambda>)input; return f.call(new Lambda<Object>() { @Override public Object call(Object input) { return x.call(x).call(input); } }); } }); } public static void main(String[] args) { Lambda<Lambda> y = yCombinator(new Lambda<Lambda>() { @Override public Lambda call(Object input) { final Lambda<Integer> fab = (Lambda<Integer>)input; return new Lambda<Integer>() { @Override public Integer call(Object input) { Integer n = Integer.parseInt(input.toString()); if (n < 2) { return Integer.valueOf(1); } else { return n * fab.call(n - 1); } } }; } }); System.out.println(y.call(10));//输出: 3628800 } interface Lambda<E> { E call(Object input); } }
这里定义了一个Lambda<E>类型, 然后通过E call(Object input)方法实现自调用,方法实现里有多处转型以及嵌套调用。逻辑比较绕,代码可读性也比较差。当然,这个问题本身也比较复杂。
我们使用Java 8的Lambda表达式来改写下匿名内部类:
package com.easy.kotlin; /** * Created by jack on 2017/7/9. */ public class YCombinator2 { public static Lambda<Lambda> yCombinator2(final Lambda<Lambda> f) { return ((Lambda<Lambda>)(Object input) -> { final Lambda<Lambda> u = (Lambda<Lambda>)input; return u.call(u); }).call( ((Lambda<Lambda>)(Object input) -> { final Lambda<Lambda> v = (Lambda<Lambda>)input; return f.call((Lambda<Object>)(Object p) -> { return v.call(v).call(p); }); }) ); } public static void main(String[] args) { Lambda<Lambda> y2 = yCombinator2( (Lambda<Lambda>)(Object input) -> { Lambda<Integer> fab = (Lambda<Integer>)input; return (Lambda<Integer>)(Object p) -> { Integer n = Integer.parseInt(p.toString()); if (n < 2) { return Integer.valueOf(1); } else { return n * fab.call(n - 1); } }; }); System.out.println(y2.call(10));//输出: 3628800 } interface Lambda<E> { E call(Object input); } }
最后,我们使用Kotlin的对象表达式(顺便复习回顾一下上一章节的相关内容)实现Y组合子:
package com.easy.kotlin /** * Created by jack on 2017/7/9. * * lambda f. (lambda x. (f(x x)) lambda x. (f(x x))) * * OOP YCombinator * */ object YCombinatorKt { fun yCombinator(f: Lambda<Lambda<*>>): Lambda<Lambda<*>> { return object : Lambda<Lambda<*>> { override fun call(n: Any): Lambda<*> { val u = n as Lambda<Lambda<*>> return u.call(u) } }.call(object : Lambda<Lambda<*>> { override fun call(n: Any): Lambda<*> { val x = n as Lambda<Lambda<*>> return f.call(object : Lambda<Any> { override fun call(n: Any): Any { return x.call(x).call(n)!! } }) } }) as Lambda<Lambda<*>> } @JvmStatic fun main(args: Array<String>) { val y = yCombinator(object : Lambda<Lambda<*>> { override fun call(n: Any): Lambda<*> { val fab = n as Lambda<Int> return object : Lambda<Int> { override fun call(n: Any): Int { val n = Integer.parseInt(n.toString()) if (n < 2) { return Integer.valueOf(1) } else { return n * fab.call(n - 1) } } } } }) println(y.call(10)) //输出: 3628800 } interface Lambda<E> { fun call(n: Any): E } }
关于Y combinator的更多实现,可以参考:https://gist.github.com/Jason...点击预览 ; 另外,关于Y combinator的原理介绍,推荐看《The Little Schemer 》这本书。
从上面的例子,我们可以看出OOP中的对接口以及多态类型,跟FP中的函数的思想表达的,本质上是一个东西,这个东西到底是什么呢?我们姑且称之为“编程之道”罢!
Y combinator 给我们提供了一种方法,让我们在一个只支持first-class函数,但是没有内建递归的编程语言里完成递归。所以Y combinator给我们展示了一个语言完全可以定义递归函数,即使这个语言的定义一点也没提到递归。它给我们展示了一件美妙的事:仅仅函数式编程自己,就可以让我们做到我们从来不认为可以做到的事(而且还不止这一个例子)。
严谨而精巧的lambda演算体系,从最基本的概念“函数”入手,创造出一个绚烂而宏伟的世界,这不能不说是人类思维的骄傲。
没有"副作用"

所谓"副作用"(side effect),指的是函数内部与外部互动(最典型的情况,就是修改全局变量的值),产生运算以外的其他结果。
函数式编程强调没有"副作用",意味着函数要保持独立,所有功能就是返回一个新的值,没有其他行为,尤其是不得修改外部变量的值。
函数式编程的动机,一开始就是为了处理运算(computation),不考虑系统的读写(I/O)。"语句"属于对系统的读写操作,所以就被排斥在外。
当然,实际应用中,不做I/O是不可能的。因此,编程过程中,函数式编程只要求把I/O限制到最小,不要有不必要的读写行为,保持计算过程的单纯性。
函数式编程只是返回新的值,不修改系统变量。因此,不修改变量,也是它的一个重要特点。
在其他类型的语言中,变量往往用来保存"状态"(state)。不修改变量,意味着状态不能保存在变量中。函数式编程使用参数保存状态,最好的例子就是递归。
引用透明性
函数程序通常还加强引用透明性,即如果提供同样的输入,那么函数总是返回同样的结果。就是说,表达式的值不依赖于可以改变值的全局状态。这样我们就可以从形式上逻辑推断程序行为。因为表达式的意义只取决于其子表达式而不是计算顺序或者其他表达式的副作用。这有助于我们来验证代码正确性、简化算法,有助于找出优化它的方法。

